
“Claude Code writes my code beautifully. I don’t need a runtime wrapped around it.”
If you’re a strong developer, you’ve thought some version of this. And you’re right. Claude Code is excellent at writing code, and with you at the keyboard it doesn’t feel like anything is missing.
Here’s the part you’re not seeing: you don’t feel the need for a layer around it because you are the layer.
You decompose the product. You open the worktrees. You keep eight sessions alive, remember which branch is safe, recover the run when it breaks, merge the two changes that collide, catch the build that’s green but quietly wrong, hand the thread back when the agent loses it. Claude Code writes the code. You run everything around it, by hand, without noticing.
That’s not Claude Code falling short. It’s doing exactly what it was built for. The question is who runs the other job: the loop around the code. Right now, that’s you.
And here is the single line that loop comes down to:
Done is not the agent saying so. A green build is not done either. Done is the behavior passing the criteria that existed before a line was written, with the evidence attached.
Hold onto that sentence. It’s the whole argument. Everything below is about who keeps that promise alive while many agents write, fail, recover and integrate over hours and days.
What work does a coding agent leave to you?
The hard part of shipping with agents was never code generation. It’s the loop around it. Split it into the work that’s actually happening, and where it lives today:
| The invisible work | Today it runs on | With PaellaDoc |
|---|---|---|
| Splitting the work into tasks | the senior’s head | versioned artifacts |
| Keeping the acceptance criteria | a chat, or memory | a contract that travels with the task |
| Routing each task to an engine | copy-paste between tabs | a governed router |
| Recovering a failed run | a human noticing | governed retry |
| Deciding “done” | intuition plus a review | a gate plus evidence |
| Holding the story together | human memory | the run’s trail |
A senior does all of it almost without noticing. The better you are, the easier it is to miss how much is still running in your head. Eight tmux panes don’t remove that work. They multiply where it happens.
Parallel agents give you throughput. They don’t give you a delivery system. If every session still needs a human to hold context, set priority, recover failure, validate output and merge the result, the human is the scheduler, the memory, the gate and the release manager, all at once.

For one expert watching every pane, that can be fine. It doesn’t survive contact with many tasks, many repos, people who don’t code, or a plan that has to outlive one chat.
What is the real bottleneck in agentic coding?
Whether Claude Code works isn’t the interesting question. Of course it works. The frontier is somewhere else now.
The frontier isn’t generating code. It’s keeping the product contract alive while many agents write, fail, recover, integrate and produce evidence.
That’s the gap I’m building PaellaDoc around. Not a better code writer. PaellaDoc runs Claude Code, Codex, Kimi and local models, because the executor was never the interesting boundary. The boundary is everything wrapped around execution: the product contract, the gates, the evidence, the recovery, the routing, the memory of what happened.
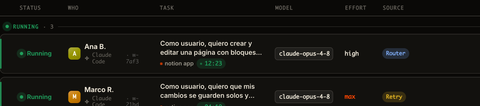
That’s the real fleet, not a mockup. Three agents at once, each in its own worktree, each from a user story. The model, the effort, and the source of the run (one routed, one recovered) are decisions the layer made, not you. That’s the work you’d otherwise be doing in your head.
Why isn’t a prompt enough to ship a product?
Most agent sessions start with a prompt. Useful, but thin. A prompt says what you want. It rarely carries the product system underneath: the spec, the criteria, the non-happy paths, the repo invariants, the gates, the evidence a change needs before it counts, the reasons the old decisions were made the way they were.
When that lives only in a chat, it rots. Only in your head, you can’t delegate it. Only in a terminal, it dies with the transcript.
So PaellaDoc makes the product contract a first-class input. Once the product work is real artifacts and not vibes, the coding loop is governed against them. The agent isn’t told to “build the thing.” It’s given a task, a contract, a gate, and what counts as evidence. The agent writes the code. The contract decides whether it counts. I wrote the long version of that in a green build is not a correct feature.
Does a bigger model fix long-running agent failures?
Long-running work breaks in a different place than demos. A real change runs through episodes: add the first behavior, keep it alive while you add the next, survive a checkpoint and resume, handle the late event, cover the negative path, hold privacy and portability, integrate at the end without quietly breaking what episode one established.
This is where “the model is smart” stops paying the bill. So I ran it.
- 4 cumulative episodes, each able to break a gate the last one fixed.
- 6 hidden gates that have to stay green the whole way: idempotency, privacy, deterministic replay, checkpoint and resume, late events, negative paths.
- Claude Code with a strong prompt: 0 of 4 episodes clean, stuck at 66.67%.
- Claude Code with a hand-written recovery skill: same, 66.67%.
- A bigger model (Sonnet, Opus, n=1 each): better first diff, still 66.67%.
- The same executor under PaellaDoc’s governed retry: 4 of 4, 100%, recovered on its own, no human in the loop.
Both Claude Code arms got stuck at exactly two thirds for the same reason: they fixed the new requirement and broke an older invariant, and nothing told them they had regressed.
The caveat, up front: a plain feedback-retry harness also reached 100%, in three attempts, and it didn’t spend fewer tokens. So this isn’t “the model got smarter.” It’s that something outside the agent held the contract, re-scored the work, and decided whether an old invariant just broke. That something is the product. Data, harness and the full caveat list are in the recovery experiment: exploratory, Haiku/low, controls at n=1. The first slice of a longer benchmark, run in the open, and not against a dumb prompt. Against a senior using Claude Code at full tilt.
What if Claude Code adds a runtime?
It might. Claude Code already ships hooks, skills, subagents, parallel sessions and review. Codex runs background tasks in its own cloud. Some of this orchestration will get absorbed, and that’s fine.
PaellaDoc doesn’t compete to be the best executor. It competes to be the layer the contract lives in: portable, local-first, multi-engine. The place where the product contract, the gates, the evidence and the memory of every run survive, no matter which agent wrote the code or which vendor you’re on this quarter.
An executor that also orchestrates is still one vendor’s executor. The contract has to sit above any single agent, or it isn’t a contract. It’s a feature you rent, on someone else’s cloud, until the terms change.
How do you fairly benchmark an agent runtime?
The fair test isn’t PaellaDoc against a weak prompt. That’s easy and useless. It’s a human-scheduler benchmark. Arm A: a senior, Claude Code, worktrees, background sessions, strong repo instructions, manual orchestration allowed. Arm B: PaellaDoc, the same executor, same model, same repo, same plan, same gates, no trick in the task.
Then count: human minutes steering, interventions, gates recovered, hidden regressions, final pass rate, evidence completeness, tokens, time to a validated result.
If the senior wins, that tells me where the layer is still weaker than a good operator, and I go fix it. If PaellaDoc wins, the point isn’t that Claude Code was bad. It’s that the contract layer was the thing that mattered. If they tie on correctness but PaellaDoc needs less steering, that might be the most useful result of the three.
So
Claude Code writes the code. Codex runs the tasks. PaellaDoc keeps the product contract alive until the work is validated, with evidence.
That’s the category. Not a faster executor. A place where “done” still means something after the agent has moved on.
Let the agent write the code. Keep the product intent and the decisions that matter. Let the contract layer carry the rest.
This is the same argument as the rest of what I build: route every task to the right engine, and the product brain that maintains itself.
Where to go deeper
Every piece of that loop is its own discipline, and I’ve pulled the ones that cost the most time into their own pieces: running several sessions at once and paying the scheduler tax, treating recovery as a first-class workflow instead of a 2am surprise, and giving agents memory that survives outside the chat so a cold session isn’t a cold start. They’re all chapters of the same operating guide for building software with AI agents.
PaellaDoc is that runtime, local-first and free. It runs Claude Code, Codex and the rest, and keeps the product contract alive until the work is validated.
How much of your day goes to keeping the contract alive instead of deciding what to build? Tell me on the forum.
Frequently asked questions
Do you need a runtime around Claude Code?
A strong developer can run Claude Code well by hand, acting as the scheduler, memory, gate and recovery loop. A delivery runtime moves that orchestration off the developer so work can span many tasks, repos and hours without a human holding it all in their head.
Why doesn’t a bigger model fix long-running agent work?
In a four-episode recovery benchmark, prompt-only and skill-only Claude Code plateaued at 66.67%, and bigger models in n=1 controls did the same. A governed recovery runtime reached 100%. The gap was not raw intelligence, it was holding the contract and recovering across episodes.
When is an AI coding feature actually done?
Not when the agent says so, and not when the build is green. Done is the behavior passing the acceptance criteria that existed before a line was written, with the evidence attached.
What if Claude Code or Codex add their own runtime?
Some orchestration will get absorbed. PaellaDoc does not compete to be the best executor; it is the portable, local-first, multi-engine layer where the product contract, gates, evidence and run memory live, above any single agent or vendor.