
A coding agent finishes a task. Tests green, build clean, diff tidy. You merge it. The question was never whether the model is smart enough. It’s whether you can trust that this run, the one in front of you, is correct, without running it yourself.
I measured that. The answer is no, not by looking.
The setup
I took a real Next.js and TypeScript app, froze it at a single commit, and wrote five small features. Each is a one-line request plus five acceptance criteria. I handed the request to four coding agents (Claude Sonnet, Claude Haiku, Codex, and Kimi), ran every combination three times, and scored the output by running the code, not by reading the diff.
A separate gate does the scoring. It re-applies each diff to a clean copy of the repo, executes the code, and checks every acceptance criterion. The agent never grades its own work. A green build counts for nothing.
A green build is not evidence of correctness
Somewhere we agreed that “it compiles and the tests pass” means done. It doesn’t. The agent wrote the code and, in the same pass, wrote the tests around it. Green means the code agrees with itself. It says nothing about whether it matches what you wanted.
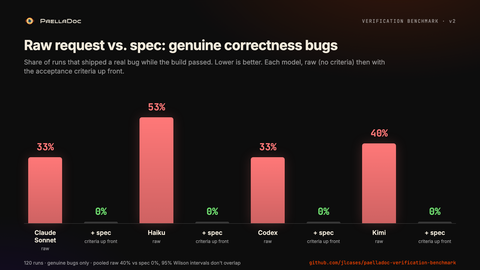
With nothing but the one-line request, 40% of runs shipped a real correctness bug. Build green, tests passing, and still wrong.
One good run proves nothing
Here’s the part that should change how you work. The same model, on the same prompt, flips. Run a task three times and you get correct, correct, broken. Across the benchmark, 15% of the cells disagreed with themselves between runs, and every unstable one was in the raw arm.
LLMs aren’t deterministic, even at temperature 0. Floating-point order and provider-side batching see to that. So “it worked when I tried it” is a single draw from a distribution you can’t see. The run you eyeballed and the run you shipped aren’t the same run.
That’s why a better model doesn’t save you. A stronger model fails less often and more plausibly, which makes the wrong runs harder to catch, not easier. The gate is what turns a lucky draw into a guarantee: it runs every diff against the criteria, every time, so “looks done” is replaced by “ran and passed.”
What closes the gap
Spec-driven development is a small idea, and an old one with a new job. It’s the BDD lineage, the product’s acceptance criteria for a user story, written executably (think Gherkin’s Given/When/Then) before the agent starts, and verified against by execution after it finishes. Not developer unit tests. The product’s definition of done, made into the gate.
I ran every task two ways. Same model, same repo, same effort. One difference: the raw arm gets the one-line request, the spec arm gets the same request plus the five acceptance criteria as a checklist. Pooled across the four models, raw shipped a genuine bug in 40% of runs. With the criteria up front, 0%. The 95% confidence intervals don’t overlap.
And then the result I didn’t expect.
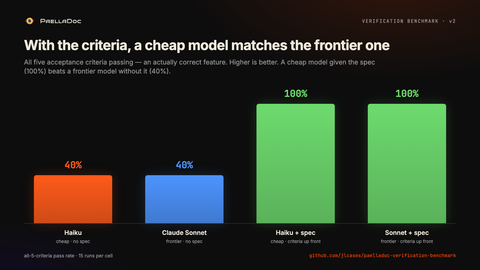
Haiku is a cheap model. Given the acceptance criteria, it hits 100%, level with the frontier model. The cheap model with a spec beat the frontier model without one. On this benchmark the spec moved the needle more than the model did. It’s the same lesson behind the dangerous illusion of AI productivity: the speed is real, the leverage is in the structure around it.
”But the model isn’t a fortune-teller”
Fair. If it fails a parameter name you never gave it, that’s on you, not a bug. That’s exactly why every criterion is tagged genuine or contract before any run, and the headline counts only the genuine ones: crashes on empty input, wrong base case, broken existing behavior, the things a competent developer gets right without being told.
The deeper version of that objection is the thesis, not a rebuttal to it. Yes, you have to tell the agent what you want, and check that it did it. That’s spec-driven development. The surprise isn’t that you must specify. It’s how many people don’t, and ship green-but-wrong code believing it’s done.
Even the strongest model is one draw
So I ran the configs a skeptic would name: Claude Opus 4.8 at high and at max effort, and Codex 5.5 at xhigh reasoning. Added after the first 120 as a labeled extension, same protocol, same gate.
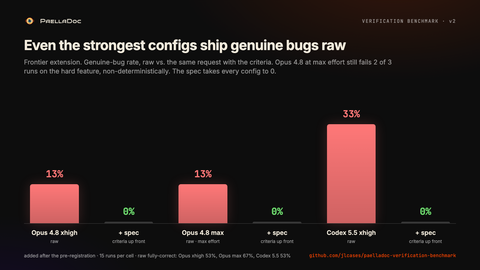
Opus 4.8 at max effort, the strongest config here, still shipped a genuine bug in 13% of raw runs, and produced a fully correct feature only 67% of the time. On the hard feature alone it failed 2 of 3 raw runs. The two Opus configs even failed on different runs of that feature, one going bug, ok, bug and the other bug, bug, ok: same model, same prompt, a different answer each time. Codex 5.5 at xhigh sat at 33% raw, the same as the Codex column in the original four. With the criteria up front, every one of them went to 0% genuine bugs and 100% correct.
The point isn’t a leaderboard. The better the model, the lower the raw failure rate, but none of them reach zero, the misses cluster on the part that’s actually hard, and they flip between runs. Even the strongest config is a single draw you can’t read without running it. The gate is what makes any of them safe to merge.
Try to break it
The repo has the protocol (written before the runs), the features, the prompts, the execution gate, and all the diffs with their verdicts. You can re-score every run without paying for a single agent call. If you find where the method falls apart, the forum thread is open and I’ll answer.
Where this leaves you
This was never an IQ test for models. It’s a measure of trust. The strong models are good. But good and verified are different claims, and on a non-deterministic system only the second one ships safely.
Write the criteria, then gate every merge on executing them. Not spec-driven, where the criteria sit in a document, but spec-gated, where they decide, so the spec becomes the contract each merge is checked against. Two things follow: you can trust the result, and a cheap model gets there too. Doing that by hand on every task is the part nobody keeps up. That’s what PaellaDoc automates, turning your intent into criteria and gating on execution. The principle holds without the tool, which is why there’s no product anywhere in the benchmark. The model you pay for matters less than the gate you don’t have.
Frequently asked questions
Does a green build mean an AI-generated feature is correct?
No. The agent wrote the code and, in the same pass, wrote the tests around it, so green means the code agrees with itself, not that it matches what you wanted. Across 120 runs on this benchmark, with only a one-line request, 40% shipped a genuine correctness bug with the build green and tests passing. Compiling and being correct are two separate claims, and a green build only checks the first.
Why does the same AI model pass a task on one run and fail on the next?
Because LLMs are not deterministic, even at temperature 0; floating-point order and provider-side batching see to that. Run a task three times and you can get correct, correct, broken. On this benchmark 15% of cells disagreed with themselves between runs. So “it worked when I tried it” is a single draw from a distribution you cannot see, and the run you eyeballed is not the run you shipped.
Does using a more capable model fix green-but-wrong code?
Not on its own. A stronger model fails less often but more plausibly, which makes the wrong runs harder to catch, not easier. Even the strongest config measured still shipped a genuine bug in a share of raw runs and flipped between runs on the hard feature. None reached zero without a gate. What drove every model to 0% genuine bugs was writing the acceptance criteria up front and checking them by execution.
How does spec-driven development make AI code trustworthy?
By turning the product’s acceptance criteria into an execution gate. You write what “done” means before the agent starts, ideally executably, then verify against it by running the code after it finishes, every time. On this benchmark the raw arm shipped a bug in 40% of runs and the arm with criteria up front in 0%, and a cheap model with a spec matched a frontier model without one. Not spec-driven, where criteria sit in a document, but spec-gated, where they decide.