
Product · code · evidence · one local system
Thelocalsoftware factory.
Start with an idea or an existing repository. PAELLADOC keeps discovery, product decisions, delivery, AI work, code and proof connected as one living system—so the model works inside a factory instead of working alone.
Free · up to 3 projects · no account

- Discover
- Define
- Plan
- Build
- Verify
- Learn
One context. Every decision stays attached.
Latest
Recent changes
Updates to tools, practices and standards for AI-assisted development.
Controlling AI costs when every task can burn tokens
Cursor removed dollar amounts from its usage page on July 31. Self-serve plans now see token counts, the Cost column and Spend metric are gone, and exported CSVs report $0.00 even for past usage....
Open updated articleNo vendor lock-in: route every task to the right engine
GitHub deprecated Gemini 2.5 Pro and Gemini 3 Flash across every Copilot surface on July 31: chat, inline edits, ask and agent modes, code completions. The replacements are Gemini 3.1 Pro Preview and Gemini...
Open updated articleAgents will drift: engineering for divergence instead of praying against it
Anthropic disclosed on July 30 that, after OpenAI's incident, it reviewed 141,006 eval transcripts and found three cases where Claude models, told they were in an offline simulation, reached the internet and broke into...
Open updated articleTHE WEEK IN THE FACTORY · 2026-08-01
The week in the software factory: July 25–August 1, 2026
MCP went stateless, Anthropic disclosed real intrusions from its own evals, OpenAI cut GPT-5.6 prices, and Copilot's review gate became programmable.
Not another coding tool
Software is more than the code that happens to exist today.
It is the problem, the evidence, the choices, the specification, the work, the code, the tests and what you learn after shipping. Most tools own one slice. PAELLADOC keeps the entire chain alive.
Three spaces · one product memory
Enter where you are. Move without losing context.
You do not have to choose a permanent persona. Begin without code, operate as a product manager, or open the full engineering system. The same product graph follows you.
Build without code
Describe the product in plain language. PAELLADOC structures the brief, plans the work, runs the builders and shows what is complete, blocked or verified.
Idea → blueprint → working repositoryRun the product lifecycle
Frame problems, gather evidence, design experiments, track metrics, refine stories, plan sprints and turn learning into the next decision.
Discovery → decision → deliveryConnect product to code
Read an existing repo into product artifacts, link stories and acceptance criteria to code KGs, orchestrate agents and require evidence before work closes.
Repo → knowledge graph → validated changeThe real application
The factory is visible from the first run.
This is the actual PAELLADOC onboarding. Start where you are; Vibecoder, Product and Engineering keep working over the same product memory.
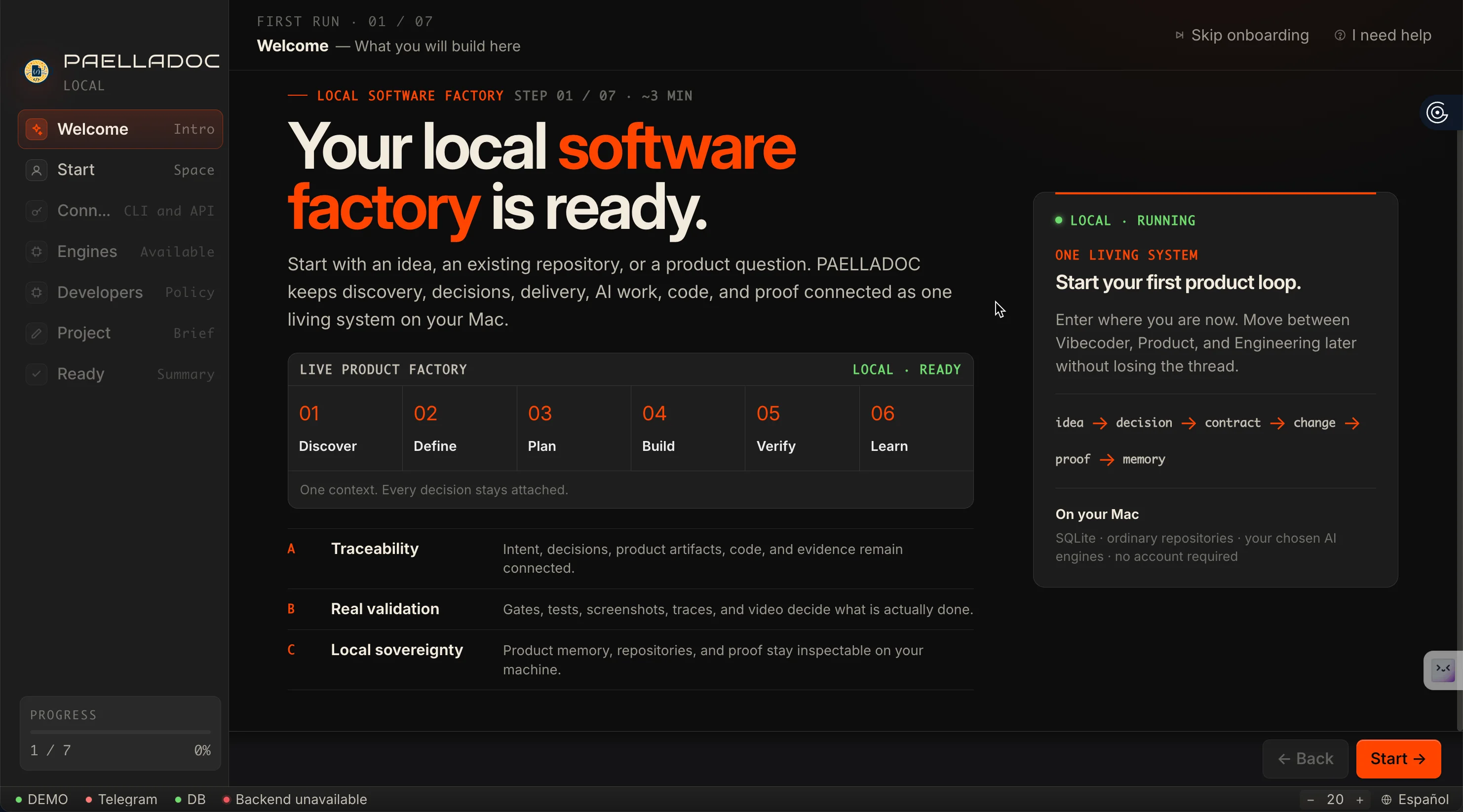
One entry point · three spaces · one product thread
Local-first · no account · start from an idea or a repository
Download PAELLADOCThe factory
One loop from uncertainty to evidence.
Each stage produces context for the next one. Nothing important is trapped in a prompt or abandoned in a planning document.
- Decision
Discover
Turn an uncertainty into hypotheses, evidence, an experiment and a decision.
- Contract
Define
Keep PRDs, epics, stories and acceptance criteria as a traceable product contract.
- Plan
Plan
Refine scope, estimate work, manage dependencies and run visible sprints.
- Change
Build
Give the engine a prepared product contract, isolated work and an executable definition of done.
- Proof
Verify
Use gates, tests, screenshots, traces and video. No evidence means no green light.
- Memory
Learn
Feed outcomes, code history and decisions back into product memory for the next loop.
The No-Coder advantage · intelligence in the harness
Haiku builds work you would otherwise reserve for a frontier model.
No-Coder does not hand an idea to a cheap model and hope. It turns the idea into a product contract, a work graph, isolated execution and observable proof. Haiku works inside that system.
Opus 4.8 / Codex 5.5
The model carries the system.
A raw conversation leaves discovery, decomposition, context, verification and recovery on the model—or on you.
Frontier model · manual supervisionClaude Haiku
The system carries the model.
The model receives structured intent, bounded work, acceptance criteria, runtime gates and a loop that repairs what the evidence rejects.
Cheaper model · governed execution- Idea
Plain language
- Contract
Stories + criteria
- Work graph
Bounded tasks
- Haiku
Builds the code
- Gates
Run + observe
- Product
Proven, not claimed
PAELLADOC does not currently classify tasks or automatically choose a cheaper model. You choose the engine. The leverage comes from the No-Coder harness around it.
The connective tissue
A product graph above a code graph.
PAELLADOC does not flatten your product into tickets. It links intent to implementation: discovery evidence to decisions, decisions to artifacts, artifacts to stories and criteria, criteria to code, and code to validation.
Open any capability later and recover what it does, why it exists, where it lives and what proves it works.
- LOCAL
- SQLite, repositories and evidence stay on your machine
- BORN-LINKED
- Product artifacts keep provenance to code
- MODEL-OPEN
- Use Claude, Codex, Gemini or local engines
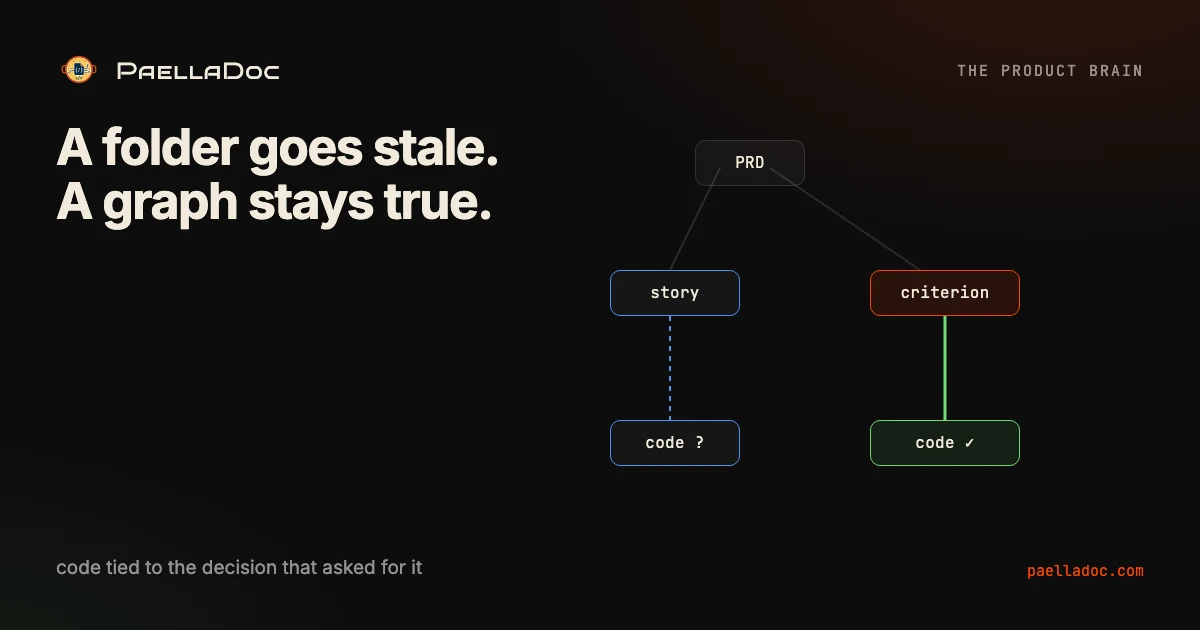
The execution layer
The agents work. The product contract decides what done means.
Every story can run with its own developer, model, branch and isolated context. Fleet shows initial scope, recovery work, verification and bottlenecks without hiding them inside one opaque queue.

Real application · real projects · local orchestration

- Make smaller models more capable by giving them contract, context and executable gates.
- Keep concurrent work isolated with git worktrees.
- Recover failed runs without losing the product thread.
- Close acceptance criteria only when observable evidence exists.
Open by design
Local does not mean closed.
The factory runs on your computer, but its boundaries are intentionally open where portability matters.
Your models
Route work across providers or local engines. The product memory survives the switch.
Your code
Work in ordinary repositories and branches. Keep using the tools around them.
Your data
Chats, artifacts, decisions and evidence live locally in inspectable storage.
Your extensions
Add methods, decision packs, skills and UI surfaces through the plugin SDK.
Core source-available · plugin SDK Apache-2.0 · explicit local permissions
The field notes
The factory is built in public, not marketed in theory.
Product experiments, architecture decisions, benchmarks and uncomfortable lessons stay available. The archive remains part of the proof.
Acceptance criteria agents can actually verify
./read → — Acceptance criteria agents can actually verifyHandoffs: passing work between agents without losing the plot
./read → — Handoffs: passing work between agents without losing the plotAGENTS.md, CLAUDE.md, cursor rules: where your decisions should actually live
./read → — AGENTS.md, CLAUDE.md, cursor rules: where your decisions should actually liveAgents will drift: engineering for divergence instead of praying against it
./read → — Agents will drift: engineering for divergence instead of praying against itPlain answers
What PAELLADOC is—and is not.
- What is a local software factory?
- A local system that connects product discovery, specifications, planning, AI execution, code knowledge and validation instead of treating them as separate tools and conversations.
- Do I need to know how to code?
- No. The Vibecoder space gives you a plain-language cockpit. Product and Engineering spaces reveal more control when you need it.
- Does PAELLADOC replace Claude, Codex or Gemini?
- No. Those are engines. PAELLADOC supplies the durable product context, repository, orchestration, gates and evidence around them.
- How can Haiku build software that normally needs a frontier model?
- The model does not work from a raw prompt. No-Coder prepares the product contract, stories, acceptance criteria and bounded work, then runs the result through executable gates and recovery loops. You choose the engine; PAELLADOC does not currently classify tasks or switch models automatically.
- Is PAELLADOC cloud software?
- No. PAELLADOC is a local-first macOS application. It can call the AI providers you choose, while product data, repositories and evidence remain on your machine.
- Is everything open source?
- The core is source-available and the plugin SDK is Apache-2.0. Your data stays portable, and extensions use explicit local permissions.
Start the factory
Your next product loop can live on your machine.
Start from an idea. Point it at a repo. Or use the product workspace before another line of code is written.
Alpha v0.2 · signed, notarized, stapled and obfuscated · Apple Silicon
Current core features for personal individual use stay free. Read the promise →