
I build a tool that injects context into a coding agent. So the useful thing I can do is show you where that does not help, with numbers.
I ran 100+ controlled runs against a real, private production backend (about 32,000 indexed code units), across four models (a cheap one, Sonnet; a frontier one at two effort levels, Opus; and the auto router, opusplan) and four task difficulties. Everything below is measured in Claude Code. The mechanism generalizes to any coding agent; the numbers are Claude Code’s, and I will be explicit about that. This is exploratory: one private target, no public reproduction yet, three repetitions per cell, with real variance.
How do you test whether context helps a coding agent?
Three arms per task, changing one thing at a time:
- bare: the agent with all of its tools and just the task. The unmutilated baseline.
- pack: the same, plus a context pack injected into the prompt: the relevant files, symbols and fragments, already located. The only difference from bare.
- pack-hard: the pack, but the agent’s search tools (grep, glob, find) are blocked and turns are capped, to force it to lean on the pack.
A “context pack” here is the observable output: what PaellaDoc puts in front of the agent. How it gets built is not the point of this piece. What it does to the run is.
Four difficulties, all with verifiable ground truth: locate a specific function (easy), explain how a business metric is computed across files (medium), trace an end-to-end flow through several services (hard), and implement a new feature and wire it in (edit). The cost anchor is the agent’s own reported spend, which prices cached versus new tokens and cross-model sub-agents correctly. Quality is coverage over a ground-truth list of symbols and files the right answer must name. Each run happens in a throwaway git worktree, so the tools never touch the real repo.
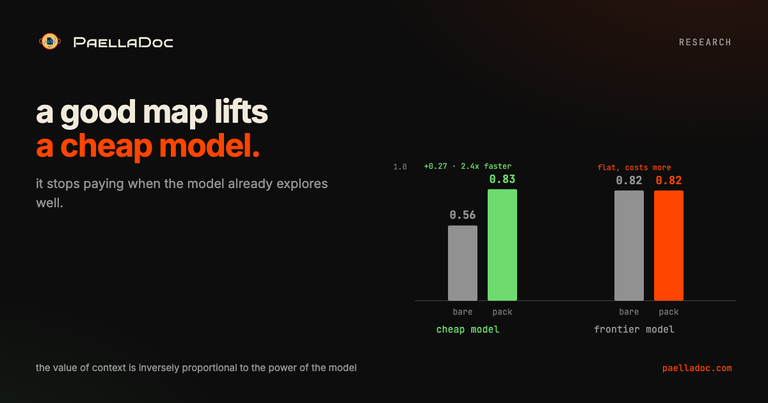
Does a context pack make a cheap model as good as a frontier model?
For reading and understanding the codebase, yes, and that is the headline.
| Reading (avg of 3 tasks) | Cost | Quality | Time |
|---|---|---|---|
| Cheap model, bare | $0.26 | 0.56 | 174s |
| Cheap model, pack | $0.24 | 0.83 | 73s |
| Frontier model, bare | $0.66 | 0.82 | 193s |
| Frontier model, pack | $0.90 | 0.82 | 86s |
A cheap model with a good map reached the quality of a frontier model running free, at the same or lower cost, and more than twice as fast. The pack is an equalizer: it raises the floor of a weak model.
The mechanism is not extra intelligence. Without the pack, the agent spawns cheap sub-agents to go exploring (it did in about 18 of 27 reading runs). With the pack, that almost stops (about 4 of 27) and it uses roughly half the tokens. The pack replaces work, it does not add brains.
Why does context stop helping the best models?
Look at the frontier row again: pack quality 0.82, same as bare, but cost went up. That one line is the whole experiment, and it cuts against me:
The value of context is inversely proportional to the power of the model.
A frontier model already explores well on its own. Handing it a map it did not need adds cost and saves it work it was happy to do. The pack pays off most exactly where the model is weakest, and least where the model is strongest.
Can too much context make a strong model worse?
Yes, and this is the finding I least wanted to publish. On the hardest task, tracing a flow end to end, a single-query pack is partial by nature. A strong model that would have traced the whole thing in freedom instead trusts the partial map and leaves parts out.
| Hardest task, quality | bare | pack | pack-hard |
|---|---|---|---|
| Cheap model | 0.20 | 0.50 | 0.67 |
| Frontier model | 0.83 | 0.47 | 0.50 |
On the hard task the pack rescues the cheap model (0.20 to 0.67) and blinds the strong one (0.83 to 0.47). Caveat: n=3 per cell, variance is high, and the two frontier-effort settings disagreed (one got worse, the other improved), so the blinding is real but noisy. Do not over-read a single cell.
Does a frontier model write better code than a cheap one?
For writing the feature, no, and I checked by running the code. The first version of this used a weak metric: did the agent edit the right files and name the right symbols? A skeptic would rightly say that proves intent, not a working algorithm. So I replaced it with objective verification.
The task was a standard pure function, calculate_max_drawdown(daily_values) -> float: the largest peak-to-trough drop in a series as a non-positive fraction (for example -0.25 for a 25% drawdown, 0.0 if it never falls below its running peak). The function and the test cases are my own design, not the target repo’s code, so they are fully publishable.
How do you know the cheap model’s code actually works?
I pulled the function out of the git diff of all 28 edit runs and ran each one against 7 canonical cases:
| Input series | Expected | Why |
|---|---|---|
[100, 50] |
-0.50 | simple 50% drop |
[100, 110, 90] |
-0.1818 | trough relative to the peak |
[100, 80, 120, 60] |
-0.50 | the larger of two drops |
[50, 100, 75] |
-0.25 | drop after a new high |
[100, 100, 100] |
0.0 | no drops |
[100, 110, 120] |
0.0 | monotonic |
[100] |
0.0 | series too short |
An implementation counts as correct only if it passes all 7 (tolerance 0.02). All 28 implementations pass 7 of 7. Sonnet included.
| Model | 7/7 correct |
|---|---|
| Sonnet | 12 / 12 |
| Auto (opusplan) | 9 / 9 |
| Opus, high effort | 5 / 5 |
| Opus, max effort | 2 / 2 |
| Total | 28 / 28 |
So the only difference left is money. Same verified-correct result, 5 to 6 times the cost:
| Model (verified 7/7) | Cost |
|---|---|
| Sonnet + PaellaDoc | $0.44 |
| Sonnet, bare | $0.56 |
| Auto (opusplan) | $0.50 |
| Opus, high effort | $2.49 |
| Opus, max effort | $2.84 |
The frontier model did not produce a better result. It produced the same correct one, 5 to 6 times more expensive, and you can replicate the check: the cases are above, the function is standard.
This verifies the function, the substance of the feature. It does not run the repo’s full test suite (wiring the function into the pipeline), because the target is private and its environment cannot be published. The end-to-end pytest verification comes with the open-source replication. n=2 to 12 per model; the “all correct” pattern is firm in what ran.
Does context make a coding agent faster?
It cuts wall-clock by removing exploration, around 1.8x on average and up to 2.4x on a cheap model. That is a different axis from “fast mode” (which speeds up token generation). They multiply: the speedup here is from doing less work, not from generating faster, so the two stack. I did not measure them together, so treat the combined number as arithmetic, not a measurement.
| Reading speed | bare | pack | speedup |
|---|---|---|---|
| Cheap model | 174s | 73s | 2.37x |
| Frontier model | 193s | 86s | 2.25x |
| Global | 184s | 100s | 1.84x |
Does Claude Code’s auto router give you Opus in CI?
No, and this one is worth knowing. The automatic router (opusplan) is supposed to pick the strong model when the task warrants it. Across 19 headless runs (--print, the path CI and SDKs use), it chose the strong model zero times. It only escalates in interactive plan-mode. In automation, auto means cheap model. If your mental model is “I set it to auto and get the best of each,” that is not what runs in your pipeline.
Should you block an agent’s search tools to force it to use context?
It backfires. Blocking grep and glob (pack-hard) did not make runs faster (about 1.0x) and sometimes lowered quality, because the agent routes around the block with sub-agents: more tokens, more variance. The lesson is the opposite of forcing. Inject context, and leave the tools alone.
Does this help local, non-frontier models?
This is where I think it matters most, and I have to be careful, because I did not measure it here. The experiment ran on cloud models, using a cheap one and a frontier one as the two ends of a capability axis. The clearest result was the equalizer: a context pack lifted the cheap model to frontier quality, at the same cost and twice as fast.
A local model, the kind you run on your own machine with no cloud, sits further down that same axis than the cheap cloud model. The inverse law says context helps most exactly there. So the fair extrapolation is that a good map should help a local model more, not less. That is the next test: the same protocol against a local model, on a desktop, offline.
If that holds, it lands on the part of PaellaDoc that was never about saving a frontier user money. It is about making a non-frontier, local, private model good enough to work on a real codebase. That is the sovereignty bet: your code and your model on your machine, with a map good enough that you do not have to rent frontier intelligence to get a reliable answer.
What this experiment does not show
- One private target, so no public reproduction yet. A reproducible version on an open-source repo is the next step.
- Quality is a keyword-coverage proxy over ground truth. The easy task saturates at 1.0; a finer LLM or human judgment pass over the saved answers is pending.
- n=3 per cell means real variance, worst on the hard task. The reading cells for the cheap and frontier models are the solid part (n=9); the edit and auto-router numbers are preliminary and marked as such, except the “auto router used the strong model 0 of 19 times” fact, which is firm.
- The cheap-versus-frontier axis used cloud models. The local-model case is an extrapolation from the equalizer effect, not a measurement, and it is the next run.
- Measured in Claude Code only. The mechanism generalizes, the numbers do not.
Who is a frontier model actually for?
A frontier model is the right tool when you cannot bring the map. That covers a lot of people: anyone less technical, anyone who does not want to engineer context, anyone for whom raw intelligence is the cheapest path to a good answer. The labs are right to build and price for that, and the audience is growing.
A developer who understands the agentic loop is not that audience. If you can supply the context, you stop needing to rent the intelligence that compensates for not having it. The benchmark is just the receipt: the same correct code, a fraction of the cost, the moment you bring the map yourself.
That is the point of understanding how agentic development works instead of treating it as a black box. The premium on a frontier model is, in part, a premium on not bringing context, and you can opt out of it. PaellaDoc is one way to bring the map: your own code, on your machine, so even a cheap or local model has enough to work with.
The one line to take away
A good map of the repo makes a cheap model perform like an expensive one, and about twice as fast, and it stops paying off the moment the model already explores well on its own. Context is not a free upgrade you bolt onto everything. It is a lever that is strongest where the model is weakest, and it can cut the wrong way on a strong model and a wide task.
That is the bet behind PaellaDoc: not a smarter model, a better map of your own code, on your machine, good enough that even a local model can do real work against a real repo. The interesting part was never “does context help,” it was “where, and where not.”
PaellaDoc is local-first and free. It runs your agent against your own repo, no cloud and no account.
This sits next to the rest of what I measure in the open: a green build is not a correct feature and long-running agents need a runtime, not a bigger model.