
For a while my setup was three terminals. Claude Code in one, Codex in another, Kimi when one of them got rate-limited. It worked, the way juggling three things works. Then I started pushing real tasks through it and the cracks showed.
A throwaway copy edit got handed the same heavy model as a database migration. Half the time I routed something to an engine that wasn’t even installed on that machine, and I only found out when it failed. I was making a runtime decision by hand, badly, on every task.
That is when “which model should I use” stopped being the question. The model is not the unit of work. The task is.
A copy edit is not a migration
A one-line UI tweak and an Alembic migration are not the same job. One can take production down. The other is five minutes of work you could hand to the cheapest model in the room. Send everything to your most expensive engine and you burn money on the trivial stuff. Send everything to the cheapest and the migration blows up in your face.
So the real questions are not about the model. They are about the work in front of you. What kind of task is this. Which engine is actually available on this machine or account. What cost and latency you accept. What happened last time you ran something like it. And what safe thing happens when the system can’t decide.
The CLIs have gotten smarter about this, and it is worth being precise. Claude Code already routes inside its own house: it plans with Opus and executes with Sonnet, and it falls back to a lighter model when you hit a limit. Codex dials its reasoning effort up and down on its own. That is real routing, and it is good.
But it is routing inside one vendor. Claude routes between Anthropic models. Codex routes between OpenAI models. Neither one is going to send your cheap task to Kimi, your migration to a frontier model, and your offline work to a local model, because that is not their job. Their job is to run their engine well. And none of them answer the product questions: availability across engines, cost across vendors, what worked in your repo, what safe thing happens when the call fails. For one-off work, in-house routing is plenty. It stops being enough the moment you want a product across engines instead of one good tool.
An engine is a lever. You still need the hand on it.
PaellaDoc does not wrap a CLI and call it another chat. It treats Claude, Codex, Kimi, Gemini, any open-source model through Ollama, or any CLI you point it at as a fleet of interchangeable engines under one contract. When a task comes in, a router picks the engine and the profile for that job: cheap, balanced, strong, or frontier.
That is the difference in one line. A CLI is a lever. PaellaDoc is the layer that decides when, how, and why to pull each one.
The week a model got pulled
A real example, from the same week I am writing this. Anthropic shipped Fable 5 on a Monday. By Thursday a US export-control order forced them to disable it and to cut off access for any foreign national, inside or outside the United States. I work from Valencia. If my product had been wired to that one model, my product was down on Thursday, by government order, with nothing I could do about it.
That is the lock-in I refuse to build on. Fable made the news. The ones that actually get you usually don’t: a price change, a new rate limit, a data retention policy you cannot accept, a model deprecated with a month of notice. When you depend on one vendor’s model, every one of those is your problem and none of them is your decision.
A fleet under one contract turns that from an outage into a config change. The engine you trusted vanishes, you route to another one, the work keeps moving. And the floor under all of it is open source: with any open-source model running locally through Ollama, nothing leaves your machine and no vendor, and no government, can switch it off. For someone in the EU handling other people’s source code, that is not a nice-to-have. It is the whole reason to build this way.
The part I am proudest of is a restraint
Here is the design decision that matters most, and it is a restraint, not a feature.
When the smart router runs, it is allowed to choose exactly two things: which agent, and which profile. That is the whole contract. It cannot pick the model. It cannot pick the reasoning effort. It cannot pick the context budget. Those come from a tested config slot, not from a language model improvising mid-flight.
This kills a whole class of failure that is everywhere in AI products: letting a model “decide” a runtime config that then does not exist, is not authenticated, or does not fit the engine it chose. In PaellaDoc the router proposes an agent and a profile. The runtime resolves the model, the effort, and the context from verified config. The smart part suggests. The boring, tested part executes.
Deterministic by default, intelligent by contract
The default mode is deliberately dumb. Rules. No extra call to an LLM just to decide a model. It is predictable, it is cheap, and when something goes wrong you can actually debug it. The intelligence is opt-in, and it sits behind a PRO license.
And even with smart mode on, the router is on a short leash. If it returns broken JSON, or picks an engine that is not installed, or names a profile that does not exist, or tries to swap the agent when one is locked, the system drops straight back to rules. No crash, no half-configured run. Deterministic by default, intelligent by contract.
That sentence is the whole philosophy. In production, intelligence without a fallback is just a debt you have not been billed for yet.
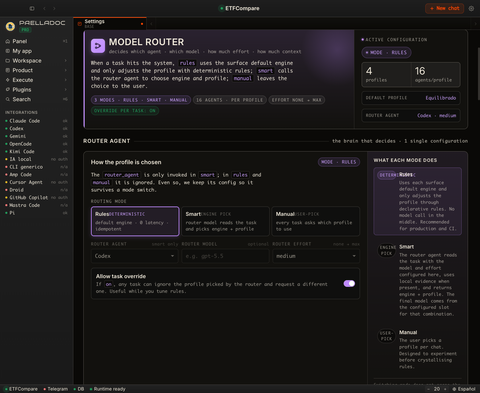
That is the actual panel, not a mockup. Rules is the active mode. The fleet runs down the left with each engine’s real availability, and the three modes are right there: deterministic by default, smart and manual one click away.
It learns, and it learns here
Over time the router stops guessing. It looks at what actually worked in your project: which engine and profile combinations passed the gate, and what they cost in tokens. Then it leans that way, carefully, only when there is enough evidence to justify it.
Two things I care about here. It learns locally. It does not ship your prompts or your terminal output anywhere to rank engines. It works from compact outcomes of what happened. And it does not believe Claude, or Codex, or Kimi is better in the abstract. It has no opinion about that. It learns which combinations worked on tasks like yours, in your repo.
It only routes to engines that can actually run
A router that offers you an engine that is not installed is worse than no router. Before the smart decision happens at all, PaellaDoc filters the candidates down to the engines the runtime can genuinely launch on this machine: the adapter exists, it reports as available, it is authenticated. If a local CLI points to a binary outside the PATH, the availability check uses that same path, so it is not wrongly thrown out.
The list the router chooses from is not a marketing catalog. It is a list of things that will actually run.
What this is really about
None of this is about a magic model that is always right. I do not believe that model exists, and a product built on the assumption that it does will break the first week.
The next generation of agent software will not differ by which model it calls. Everyone calls the same handful. It will differ by the quality of its decision layer: how it picks, when it escalates, what it learns, what it blocks, and how it fails. That layer is the product.
A CLI runs one vendor’s engine, and runs it well. PaellaDoc governs a fleet of them, and keeps the choice yours.
This is the deep version of one row in the comparison hub: model-agnostic, your engine, your machine. And it is the same argument as the rest of what I build: the product brain that maintains itself, and a green build is not a correct feature.
Do you route across engines or commit to one? Tell me on the forum, I want to hear how you handle it.
Frequently asked questions
What is model routing for AI coding agents?
Model routing treats the task, not the model, as the unit of work. When a task comes in, a router picks which engine runs it and at what profile — cheap, balanced, strong or frontier — based on the kind of task, which engines are actually available, the cost and latency you accept, and what worked before. A copy edit and a database migration are not the same job, so they should not default to the same expensive engine.
How do I avoid vendor lock-in with AI models?
Treat engines as a fleet under one contract instead of wiring your work to a single model. When a provider changes pricing, adds a rate limit, or a model gets pulled — as happened the week an export-control order disabled one mid-week — you route to another engine and the work keeps moving, turning an outage into a config change. The floor under it is open source: a local model through Ollama that no vendor or government can switch off.
Should I use one AI model or route across several?
For one-off work, a single CLI routing inside its own vendor is plenty — Claude Code plans with one model and executes with another. It stops being enough when you want a product across engines: none of them will send your cheap task to one engine, your migration to a frontier model, and your offline work to a local one, or answer availability, cost and fallback across vendors. The decision layer across engines is the product.
Can a router send work to a model that is not installed?
It should not, and a good one does not. A router that offers an engine that cannot launch is worse than no router. Before any smart decision, the candidates are filtered to engines the runtime can genuinely start on this machine: the adapter exists, reports available, and is authenticated. And when a smart router does run, it only picks the agent and profile — the model, effort and context come from verified config, with a deterministic rules fallback if anything breaks.