
A team asks Claude Code whether their repo actually covers a real user pain. The answer comes back fast, sharp, and fair. Then they ask Compass the same thing, and get a different read, one wired into the map of what the product already is. Both are partly right.
The interesting question is not which AI wins that one exchange. It is what kind of system a team needs to keep deciding well, over months, not in a single chat.
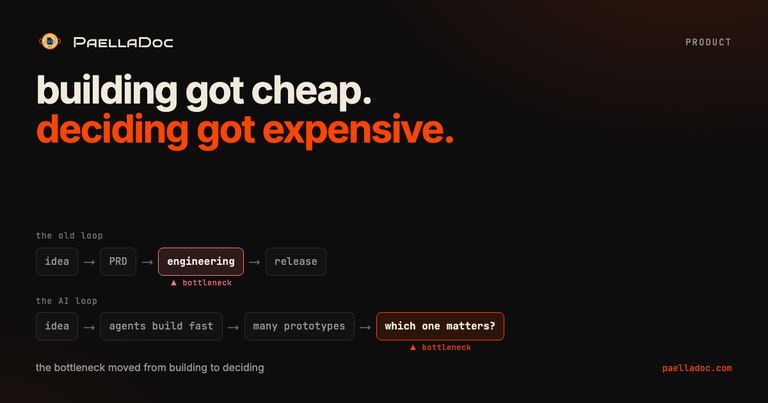
Building got cheap. Deciding got expensive.
For years a big chunk of the cost sat in turning an idea into code. With agents like Claude Code, Codex, Cursor or Kimi, building is much cheaper and faster. That does not make product work less important. It makes it more demanding.
If anyone can build faster, the edge is no longer producing features. It is deciding better what to build, with what evidence, under which assumptions, and how to learn before you accumulate product debt.
Cheap building has a trap in it. You can now generate more screens, more epics, more experiments, more code. And more product debt. If the team does not upgrade its decision system at the same rate, all that speed just accelerates the dispersion.
That is the new bottleneck. Not typing. Deciding, and learning.
The old playbook still holds. The bar went up.
This is not the part where someone announces that the classics are obsolete. They are not.
Value, viability, usability and feasibility are still the job. Continuous discovery still beats arguing about one inevitable-looking solution. A shared metric that captures real user value still keeps a team from speaking four different languages. The lineage from Cagan, Torres and the North Star people did not get replaced by AI. The AI era raises the bar on all of it, because faster code and faster design do not guarantee better outcomes. The hard work, finding valuable and viable solutions, needs more judgment, not less.
What is new is where that judgment has to live. Not in a static document that goes stale the day after it is written.
In the AI era, the PRD stops being the document that precedes the product. It becomes a living system that evaluates, remembers and corrects the product’s decisions.
What actually changes
The shape of the work moves on six fronts:
- from exploring one solution to exploring many routes
- from a PRD to an evaluable prototype
- from opinion to evals
- from document search to a graph of relations
- from a static roadmap to a decision ledger
- from “the PM writes requirements” to “the PM designs the system that learns”
None of these removes the human. They change what the human is responsible for. In a world of agents, the product person stops being the one who writes the spec and becomes the one who designs the decision loop.
Where Compass fits
Compass is the product-reasoning layer inside PaellaDoc. It reads your repo, your artifacts, your decisions and your conversations, and it connects five things:
- As-built map, what actually exists in the repo.
- Provenance, where each artifact came from.
- Semantic graph, how capabilities, risks, decisions and evidence relate.
- Future bets, the candidate directions that follow from all of it.
- Product evals, how you know whether a recommendation was any good.
The point is what it refuses to do. It does not hand you a strategy and call it truth.
Compass does not say “this is the strategy.” It says: this is what can be inferred, this is what is not known, these are the candidate bets, and this is the minimum validation before you build more.
Reverse intake shows what got built, not why it matters
A reverse intake is not discovery. It does not talk to users, it does not measure pain, and it does not reconstruct the team’s original intent. Its value is different: it shows what product has actually been built. That as-built map, plus provenance and relations, is enough to spot capabilities, gaps and decision debt. From there, the job is not to dictate a strategy. It is to form candidate bets and name what to validate before building more.
Which means not every source earns the same kind of claim. This is the part most product graphs get wrong:
| What you want to claim | What it needs | What can support it |
|---|---|---|
| “Users actually feel this pain” | real users, usage, validation | external evidence, validation runs |
| “We decided this on purpose” | human-authored docs, decisions | natural, human-authored sources |
| “This capability exists” | the built product | reverse intake |
| “This is how it’s implemented” | the code | raw code |
The rule Compass holds itself to: a reverse-intake node can support this exists. It cannot support this matters to the user. A pretty graph of nodes is not evidence. The ordered bet, scored by what evidence actually backs it, is.
Claude Code diagnoses. Compass remembers.
This is not a fight between models, and Compass is not “the smarter one.” Claude Code direct is excellent at the thing it is for: read raw code with precision, surface sprawl and debt, answer a sharp technical or local question, no intermediate layer needed. For ad-hoc diagnosis, reach for it.
Its limit is continuity. The context gets rebuilt every chat. There is no structured provenance, no reusable decision history, no persistent artifact graph, no comparison across versions, no repeatable product evals. The answer is good and then it evaporates.
Compass is the infrastructure for the part that has to persist:
| Claude Code direct | Compass |
|---|---|
question → repo scan → good answer → context gone |
question → graph + provenance + history → answer → artifact → eval → decision ledger → better next answer |
The difference is not that Compass thinks better than Claude Code on one isolated question. It is that Compass turns product reasoning into a system that is persistent, auditable, and able to improve.
Evals are the new living PRD
In AI products, quality is not controlled by deterministic tests alone. You have to define what a good answer is, which failures are unacceptable, and what evidence can hold up a recommendation. That is why evals start to look like living PRDs: they do not describe a feature once, they continuously check whether the product behaves as promised.
So every Compass answer that recommends a direction should itself be checkable: did it keep provenance straight, did it separate evidence from hypothesis, did it propose a concrete next validation, did it avoid unsupported strategic certainty. This is the same bet as the rest of what I build, where the spec, not the model’s vibes, is what makes the output trustworthy. I measured that in the verification benchmark: raw, the model ships errors; with the contract written down, it does not.
The advantage that compounds
The new product edge is not an AI that answers once. It is a system that remembers, connects, questions and evaluates each product decision over time.
The future of product management is not humans versus agents. It is designing a system where the agents build, the graph remembers, the evals correct, and people stay responsible for judgment. The PM does not disappear. They become the designer of the decision loop.
I wrote about keeping the product contract alive while agents do the writing, in you are the runtime. This is the other half: generating the right contract in the first place, and being clear about what you can and cannot yet claim. Compass is that layer for PaellaDoc. Not an AI that pretends to hold the truth. A system that helps you find it faster.
If building is cheap now, what is the slowest, most expensive decision your team keeps re-making from scratch? Tell me on the forum.