
“Claude Code me escribe el código de lujo. No necesito un runtime por encima.”
Si eres bueno, has pensado alguna versión de esto. Y tienes razón. Claude Code escribe código de sobra, y con el teclado delante no sientes que falte nada.
Esto es lo que no estás viendo: no sientes que necesites una capa por encima porque la capa eres tú.
Partes el producto en tareas. Abres los worktrees. Mantienes ocho sesiones vivas, recuerdas qué rama es segura, recuperas el run cuando se cae, integras los dos cambios que chocan, pillas el build que está verde pero mal por debajo, le devuelves el hilo al agente cuando se pierde. Claude Code escribe el código. Todo lo de alrededor lo corres tú, a mano, sin darte cuenta.
Eso no es que Claude Code se quede corto. Hace justo para lo que está hecho. La pregunta es quién corre el otro trabajo: el bucle de alrededor del código. Ahora mismo, eres tú.
Y esta es la única frase a la que se reduce ese bucle:
Done no es que el agente lo diga. Un build verde tampoco es done. Done es el comportamiento pasando los criterios que existían antes de escribir una línea, con la evidencia pegada.
Quédate con esa frase. Es el argumento entero. Todo lo de abajo va de quién mantiene viva esa promesa mientras muchos agentes escriben, fallan, recuperan e integran durante horas y días.
¿Qué trabajo te deja a ti un agente de código?
La parte difícil de entregar con agentes nunca ha sido generar el código. Es el bucle de alrededor. Pártelo en el trabajo que de verdad está pasando, y dónde vive hoy:
| El trabajo invisible | Hoy corre en | Con PaellaDoc |
|---|---|---|
| Dividir el trabajo en tareas | la cabeza del senior | artefactos versionados |
| Mantener los criterios de aceptación | un chat, o la memoria | un contrato que viaja con la tarea |
| Enrutar cada tarea a un motor | copia-pega entre pestañas | un router gobernado |
| Recuperar un run fallido | un humano que lo nota | retry gobernado |
| Decidir “done” | intuición y una revisión | un gate y evidencia |
| Mantener la historia entera | memoria humana | el rastro del run |
Un senior hace todo eso casi sin notarlo. Cuanto mejor eres, más fácil es no ver cuánto sigue corriendo en tu cabeza. Ocho paneles de tmux no quitan ese trabajo. Multiplican los sitios donde pasa.
Los agentes en paralelo te dan throughput. No te dan un sistema de entrega. Si cada sesión sigue necesitando a un humano que sostenga el contexto, ponga prioridad, recupere el fallo, valide la salida e integre el resultado, el humano es el scheduler, la memoria, el gate y el release manager, todo a la vez.

Para un experto vigilando cada panel, puede valer. No aguanta el contacto con muchas tareas, muchos repos, gente que no programa, o un plan que tiene que durar más que un chat.
¿Cuál es el verdadero cuello de botella del coding con agentes?
Si Claude Code funciona no es lo interesante. Claro que funciona. La frontera ya está en otro sitio.
La frontera no es generar código. Es mantener vivo el contrato de producto mientras muchos agentes escriben, fallan, recuperan, integran y producen evidencia.
Ese es el hueco sobre el que construyo PaellaDoc. No un escritor de código mejor. PaellaDoc ejecuta Claude Code, Codex, Kimi y modelos locales, porque el executor nunca ha sido la frontera interesante. La frontera es todo lo que envuelve a la ejecución: el contrato de producto, los gates, la evidencia, la recuperación, el routing, la memoria de lo que ha pasado.
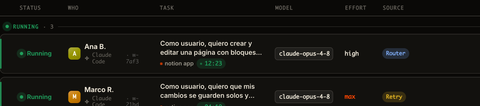
Esa es la flota real, no un mockup. Tres agentes a la vez, cada uno en su worktree, cada uno saliendo de una user story. El modelo, el esfuerzo y el origen del run (uno enrutado, otro recuperado) son decisiones que ha tomado la capa, no tú. Ese es el trabajo que si no estarías haciendo en tu cabeza.
¿Por qué un prompt no basta para entregar producto?
Casi toda sesión con agente empieza con un prompt. Útil, pero pobre. Un prompt dice qué quieres. Rara vez carga el sistema de producto que hay debajo: la spec, los criterios, los caminos no felices, los invariantes del repo, los gates, la evidencia que necesita un cambio antes de contar, las razones por las que las decisiones viejas se han tomado así.
Cuando eso vive solo en un chat, se pudre. Solo en tu cabeza, no lo puedes delegar. Solo en una terminal, muere con el transcript.
Por eso PaellaDoc hace del contrato de producto una entrada de primera clase. Cuando el trabajo de producto son artefactos de verdad y no intuiciones, el bucle de código se gobierna contra ellos. Al agente no se le dice “construye la cosa”. Se le da una tarea, un contrato, un gate, y qué cuenta como evidencia. El agente escribe el código. El contrato decide si cuenta. La versión larga la he escrito en un build verde no es una feature correcta.
¿Un modelo más grande arregla los fallos en trabajo largo?
El trabajo largo se rompe en otro sitio que las demos. Un cambio real pasa por episodios: añade el primer comportamiento, mantenlo vivo mientras añades el siguiente, sobrevive a un checkpoint y resume, gestiona el evento que llega tarde, cubre el camino negativo, mantén privacidad y portabilidad, integra al final sin romper en silencio lo que ha dejado el episodio uno.
Aquí “el modelo es listo” deja de pagar la cuenta. Así que lo he corrido.
- 4 episodios acumulativos, cada uno capaz de romper un gate que ha arreglado el anterior.
- 6 gates ocultos que tienen que seguir verdes todo el camino: idempotencia, privacidad, replay determinista, checkpoint y resume, eventos tardíos, caminos negativos.
- Claude Code con un prompt fuerte: 0 de 4 episodios limpios, clavado en 66,67%.
- Claude Code con una skill de recuperación hecha a mano: igual, 66,67%.
- Un modelo más grande (Sonnet, Opus, n=1 cada uno): mejor primer diff, sigue en 66,67%.
- El mismo executor bajo el retry gobernado de PaellaDoc: 4 de 4, 100%, recuperado solo, sin humano en el bucle.
Los dos brazos de Claude Code se han quedado clavados en dos tercios exactos por la misma razón: arreglaban el requisito nuevo y rompían un invariante viejo, y nada les decía que habían regresado.
El matiz, por delante: un harness de feedback-retry casero también ha llegado al 100%, en tres intentos, y no ha gastado menos tokens. Así que esto no es “el modelo se ha vuelto más listo”. Es que algo fuera del agente ha sostenido el contrato, ha re-puntuado el trabajo y ha decidido si un invariante viejo acababa de romperse. Ese algo es el producto. Datos, harness y la lista entera de matices están en el experimento de recuperación: exploratorio, Haiku/low, controles a n=1. El primer tramo de un benchmark más largo, en abierto, y no contra un prompt tonto. Contra un senior usando Claude Code a tope.
¿Y si Claude Code añade un runtime?
Puede. Claude Code ya trae hooks, skills, subagentes, sesiones en paralelo y revisión. Codex corre tareas en background en su propia nube. Parte de esta orquestación se va a absorber, y está bien.
PaellaDoc no compite por ser el mejor executor. Compite por ser la capa donde vive el contrato: portable, local-first, multi-motor. El sitio donde el contrato de producto, los gates, la evidencia y la memoria de cada run sobreviven, da igual qué agente ha escrito el código o en qué proveedor estás este trimestre.
Un executor que además orquesta sigue siendo el executor de un proveedor. El contrato tiene que estar por encima de cualquier agente, o no es un contrato. Es una feature que alquilas, en la nube de otro, hasta que cambian los términos.
¿Cómo se mide de forma justa un runtime de agentes?
El test justo no es PaellaDoc contra un prompt flojo. Eso es fácil e inútil. Es un human-scheduler benchmark. Brazo A: un senior, Claude Code, worktrees, sesiones en background, instrucciones fuertes del repo, orquestación manual permitida. Brazo B: PaellaDoc, el mismo executor, mismo modelo, mismo repo, mismo plan, mismos gates, sin trampa en la tarea.
Y cuentas: minutos humanos dirigiendo, intervenciones, gates recuperados, regresiones ocultas, tasa de aprobado final, completitud de la evidencia, tokens, tiempo hasta un resultado validado.
Si gana el senior, me dice dónde la capa aún es más débil que un buen operador, y voy y lo arreglo. Si gana PaellaDoc, el punto no es que Claude Code fuera malo. Es que la capa del contrato era lo que importaba. Si empatan en corrección pero PaellaDoc necesita menos dirección, ese puede ser el resultado más útil de los tres.
Entonces
Claude Code escribe el código. Codex ejecuta las tareas. PaellaDoc mantiene vivo el contrato de producto hasta que la cosa está validada, con evidencia.
Esa es la categoría. No un executor más rápido. Un sitio donde “done” sigue significando algo después de que el agente se haya ido.
Deja que el agente escriba el código. Quédate la intención de producto y las decisiones que importan. Deja que la capa del contrato cargue con el resto.
Es el mismo argumento que el resto de lo que construyo: enruta cada tarea al motor correcto, y el cerebro de producto que se mantiene solo.
Para profundizar
Cada pieza de ese bucle es su propia disciplina, y las que más tiempo cuestan las he sacado a piezas aparte: llevar varias sesiones a la vez y pagar el coste de ser el scheduler, tratar la recuperación como un flujo de primera en vez de una sorpresa a las 2 de la mañana, y darle a los agentes memoria que sobreviva fuera del chat para que una sesión fría no sea un arranque en frío. Todas son capítulos de la misma guía operativa para construir software con agentes de IA.
PaellaDoc es ese runtime, local-first y gratis. Ejecuta Claude Code, Codex y los demás, y mantiene vivo el contrato de producto hasta que la cosa está validada.
¿Cuánto de tu día se va en mantener vivo el contrato en vez de decidir qué construir? Cuéntame en el foro.
Preguntas frecuentes
¿Necesitas un runtime alrededor de Claude Code?
Un buen desarrollador puede correr Claude Code a mano, haciendo de scheduler, memoria, gate y bucle de recuperación. Un runtime de entrega se lleva esa orquestación fuera del desarrollador para que el trabajo abarque muchas tareas, repos y horas sin un humano sosteniéndolo todo en la cabeza.
¿Por qué un modelo más grande no arregla el trabajo largo con agentes?
En un benchmark de recuperación de cuatro episodios, Claude Code con prompt y con skill se quedó en el 66,67%, y los modelos más grandes en controles n=1 hicieron lo mismo. Un runtime de recuperación gobernado llegó al 100%. La brecha no era inteligencia bruta, era sostener el contrato y recuperar a través de episodios.
¿Cuándo está de verdad hecha una feature?
No cuando el agente lo dice, ni cuando el build está verde. Done es el comportamiento pasando los criterios de aceptación que existían antes de escribir una línea, con la evidencia pegada.
¿Y si Claude Code o Codex añaden su propio runtime?
Parte de la orquestación se absorberá. PaellaDoc no compite por ser el mejor executor; es la capa portable, local-first y multi-motor donde viven el contrato de producto, los gates, la evidencia y la memoria de cada run, por encima de cualquier agente o proveedor.