
This is an exploratory benchmark, and I am going to be precise about what it shows and what it does not. The full data, the harness, and the claim boundary are in the open repository.
The setup: a marathon, not a one-shot task
Most coding benchmarks give the agent one task and grade the result. That is not where long-running work breaks.
So this one is cumulative. Four episodes, run in sequence. Each episode adds new behavior, but the hidden gates from every earlier episode stay active: idempotency, privacy, deterministic replay, checkpoint and resume, late events, negative paths. The agent has to keep all of it green while adding the next thing. The final score is how many gates are still passing at the end.
That is the real shape of long work. You are never adding to a blank page. You are adding to a system that already has invariants, and the question is whether you break them as you grow.
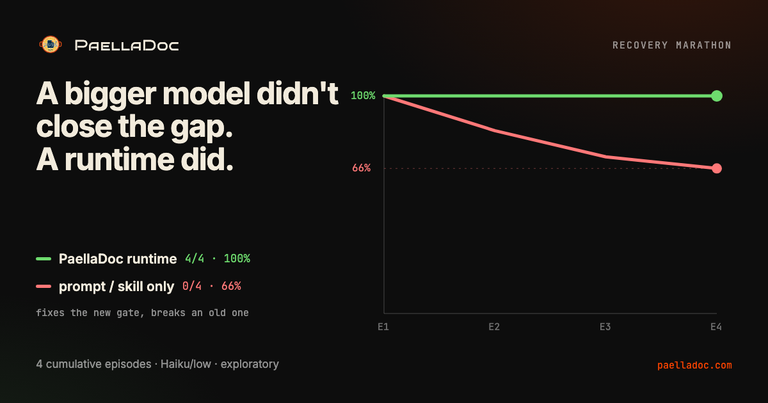
What happened on Haiku/low
Three arms, same model and effort, four complete replicates (a fifth was partial and excluded from the claims).
| Arm | Full passes | Mean final score | Recovery attempts |
|---|---|---|---|
| Claude Code (strong instructions) | 0/4 | 66.67% | 0 |
| Claude Code (local recovery skill) | 0/4 | 66.67% | 0 |
| PaellaDoc runtime | 4/4 | 100% | ~5 |
Read the 66.67% carefully, because the number alone hides the story. It is not random underperformance. Both Claude Code arms got stuck at exactly two thirds, every time, for the same reason: they fixed the new requirement and broke an older invariant. Add the late-event handling, regress idempotency. Add the negative path, lose deterministic replay. They never recovered, because nothing told them they had regressed.
The PaellaDoc runtime reached 100% on all four. Not because the model was smarter, it was the same Haiku at the same effort. Because when a gate went red, the runtime caught it, re-scored, and recovered before moving on.
A bigger model did not fix it
The obvious objection: maybe the baseline just needs a stronger model. So I ran the same prompt-only and skill-only arms on Sonnet/low and Opus/low.
Both failed at 66.67%, same as Haiku. n=1 each, so treat it as a directional control rather than proof. But it points the same way: the gap here is not raw intelligence. A more capable model still fixes the new thing and breaks the old one if nothing governs the recovery.
The part that cuts against me
Here is the result that matters most, and it cuts against me.
I gave Claude Code a custom harness: the recovery skill plus an external scorer-feedback retry loop. No PaellaDoc capsule, no runtime, just re-score and retry. On a Haiku/low n=1 run, it passed. 100%, in three recovery attempts.
So the recovery behavior is not exclusive magic, and the advantage is not a secret prompt. A team can hand-build a retry harness and get there. What the benchmark actually shows is narrower: the value is in productizing and governing that recovery loop so every team does not have to build and maintain their own.
And on cost: PaellaDoc is not cheaper here. In the audited single-run comparison it used 9.52M tokens against 8.54M for the feedback-retry harness, slightly higher, same order of magnitude. I am not going to claim a cost win this data does not support.
What I will and will not claim
I will claim this:
PaellaDoc does not make Claude smarter. It turns Claude Code into a recoverable, auditable, governed delivery runtime for long-running work: capsule state, a re-score loop, usage accounting, an evidence ledger, and continuity across episodes.
The advantage is the governed recovery loop. A sharper prompt does not get you there, and a bigger model did not either. Long-running agent work needs a runtime.
I will not claim PaellaDoc is cheaper, that it beats every Claude Code setup, that Claude Code cannot do this, or that a single hard benchmark proves a general result. The strongest fair control is the feedback-retry harness, and it passed. To turn “beats a prompt” into “productizes recovery better than a custom harness” needs an audited n≥5 run of PaellaDoc against feedback-retry on the same model, same gates, same token audit. That study is next, and it gets published the same way: in the open, with the caveats first.
This is the same argument as the rest of what I build: a green build is not a correct feature, and a bigger model is not the decision layer. Here it is measured.
All of it, including the partial replicate and the token audit, is in the repository.