
This is not Claude Code versus PaellaDoc. PaellaDoc runs Claude Code. So the real question is not which one you pick, it is what changes when the same Claude Code runs inside PaellaDoc instead of straight in your terminal. On its own, you prompt it, you read the diff, you decide if it is right, one repo at a time, at your keyboard. Inside PaellaDoc, that same agent runs in an isolated worktree, its output has to pass a gate it does not control, and the work becomes a versioned product artifact you can compare later.
What Claude Code does
Claude Code is Anthropic’s command-line coding agent. You run it in your terminal, it reads your repo, plans, edits files, runs commands, and iterates using Claude models. It is very good at the core job: writing and editing code. It holds context across a codebase, it can run your tests and react to what they print, and it stays out of your way while it works. For the act of producing a change, it is one of the best tools available today, and PaellaDoc does not try to do that job better. It hands that job to Claude Code.
What Claude Code is built to do is produce a result you then judge. You are the gate. You read the diff, you run the app, you decide whether it actually did what you asked. That works well when you are at the keyboard, watching, in one repo, with the time to check. It is the part that gets thin when there are ten tasks, a hundred repos, or a person on the other end who cannot read a diff at all.
What PaellaDoc does
PaellaDoc is a local-first layer that sits around the agent. It runs Claude Code (or Codex, or Kimi, or any CLI agent) in an isolated git worktree on your machine, model-agnostic, on your own subscription. Three things happen there that do not happen when you run the agent alone.
First, the execution gate. Before a task is allowed to reach done, PaellaDoc runs the resulting code against acceptance criteria you wrote first. Not a build check, not “the tests the agent wrote are green”. An independent run of the real behavior against the spec. If it does not pass, it is not done, no matter how confident the agent was.
Second, the work becomes product. The acceptance criteria, the user stories, the epics, the PRD, they live as versioned .paella artifacts you can diff, compare, and reuse. You make product, not just code.
Third, reach. The same agent run is one of several you can route per task, it can be driven by a no-coder who describes what they want, and you can start it, check a gate, or approve a step from Telegram, across every repo on your machine from one control room.
The key difference: who decides “done”
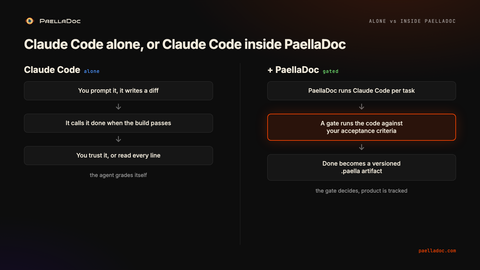
When you run Claude Code on its own, you decide done. You are reliable until you are tired, or busy, or it is the third repo of the afternoon and the diff looks plausible. When Claude Code runs inside PaellaDoc, an independent execution gate decides done, and it decides the same way every time, against criteria written before the agent saw the task. The agent’s confidence does not enter into it. The build passing does not end it. The feature has to actually do the thing.
That is the whole shift. Same model, same code-writing quality, but the judgment of whether the work is correct moves off your shoulders and onto a repeatable check that runs the code.
We have numbers for why that matters. In a public 210-run benchmark, a raw agent’s output passed the build but was genuinely wrong about 40% of the time. Even the strongest frontier model at maximum effort failed a hard task two times out of three, and it failed on different runs each time, so you could not predict which attempt would be the bad one. The full write-up is here: a green build is not a correct feature. The gate exists because the agent being good at writing code does not mean the code does what you asked.
Code, or product
Run an agent alone and you get a diff. Good diffs, often. But the requirements, the acceptance criteria, the reasoning behind a feature, those live in your head or in a chat log that scrolls away. PaellaDoc writes them down as first-class artifacts. A method pack defines how you work, a stack pack carries your tech choices, a design pack holds your tokens and theming, a validator pack is the gate itself. The community builds and shares these through an open SDK, and they are versioned, so the product context survives past the session that created it. PaellaDoc also does reverse intake: point it at an existing repo and it reads the code to reconstruct the product context that was never written down.
PaellaDoc does not replace Claude Code, it runs it
This is the part to be clear about. There is no either-or. PaellaDoc is not an alternative to Claude Code, it is a place to run Claude Code with a gate around it and a product layer underneath it. If Claude Code ships a better model tomorrow, PaellaDoc benefits the same day, because it is the agent doing the writing. You keep your subscription, you keep the agent you like, and you add the worktree isolation, the independent verification, and the artifacts. Claude Code stays excellent at its job. PaellaDoc just stops being you the moment the diff lands.
What we share
Both run real coding agents on real repos, locally, on your own machine and your own model access. Both respect that the agent should do the writing. And to be clear about where Claude Code is ahead: it is a mature, funded, polished product from Anthropic, with the engineering and the model team behind it. PaellaDoc is early, built by a solo founder, rough in places Claude Code is smooth. If you want the most refined agent experience at the keyboard right now, that is Claude Code, and PaellaDoc runs it precisely so you do not have to give that up.
| Capability | Claude Code | PaellaDoc |
|---|---|---|
| Writes and edits code with a frontier model | Yes | Runs Claude Code for this |
| Runs locally on your own subscription | Yes | Yes |
| Reads an existing repo for context | Yes | Yes (plus reverse product intake) |
| Independent execution gate vs acceptance criteria | No (you judge the diff) | Yes |
| ”Done” decided by running code, not a green build | No | Yes |
| Versioned product artifacts (PRD, epics, stories, AC) | No | Yes (.paella) |
| Isolated git worktree per task | Manual | Yes, automatic |
| Route multiple agents per task | No (single agent) | Yes (Claude Code, Codex, Kimi, any CLI) |
| No-coder mode (build from a description) | No | Yes |
| Telegram remote control | No | Yes |
| Multi-repo control room | No | Yes |
| Product maturity, polish, funding, scale | Ahead | Early, solo founder |
Who each is for
Use Claude Code on its own when you are a developer at your keyboard, in a repo you know, and you are the one who will read the diff and run the app. It is fast, it is good, and the loop of prompt, read, accept is exactly what it is built for. For that, you do not need anything around it.
Reach for PaellaDoc when you stop being able to be the gate yourself. When there are too many tasks or too many repos to check each one by hand. When a non-developer needs to ship something and cannot read a diff. When you want the product, the criteria and the artifacts, to outlive the chat. When “it built” is not good enough and you need “it does the thing”, verified by something other than the agent that wrote it. See the full compare hub for how it lines up against other tools.
PaellaDoc is not better than Claude Code. It is doing a different job. Claude Code writes the code, and writes it well. PaellaDoc runs that code in a sandbox, checks it against what you actually asked for, and keeps the product around it. You are not choosing between them. You are deciding whether the agent runs alone, or runs with a gate.