
Antigravity and PaellaDoc sit on the same layer of the stack, autonomous agents that plan, write, and check code, but they are built on opposite bets. Antigravity is Google’s bet: one model, one cloud, agents that grade their own work in their own browser, at a scale a solo founder cannot touch. PaellaDoc is the other bet: any model you want, on your machine, and a gate that decides “done” by running your acceptance criteria, written before the agent started. This is a comparison of those two bets, written by the person making the smaller one.
What Antigravity does
Antigravity is Google’s agent-first development platform, announced at Google I/O 2026. It is a real product with real range: a standalone desktop IDE, a CLI, an SDK, a managed-agents tier inside the Gemini API, and an enterprise path. It runs on Gemini, with Gemini 3.5 Flash as the default.
The center of it is genuinely impressive. Multiple agents plan the architecture, write the code, and then test it live in a real Chrome browser. A Browser Subagent clicks buttons, fills forms, takes screenshots, and debugs against what it sees on screen, then the system deploys, while you watch. It runs dynamic subagents in parallel, schedules background tasks, and takes voice commands. In the onstage demo it built an operating system in about twelve hours with 93 subagents.
That live-browser self-testing is a real step. An agent that opens the thing it built, clicks through it, and reads the screen is doing more than emitting a green build. Google’s speed, polish, and resources here are not something I am going to pretend to match.
What PaellaDoc does
PaellaDoc is a local-first orchestration and verification layer, plus a product layer, for AI coding. It runs coding agents (Claude Code, Codex, Kimi, any CLI agent) in isolated git worktrees on your machine. It is model-agnostic and bring-your-own-subscription.
The part that matters most is the execution gate. In PaellaDoc, “done” is not a green build and it is not the agent saying it is done. You write acceptance criteria first. The gate runs the produced code against those criteria, on the real diff, and that run is what moves a card to done.
Around the gate sits the product layer: a PRD, epics, user stories, and acceptance criteria become versioned, comparable .paella artifacts. There is a reverse intake that reads an existing repo and reconstructs its product context, a multi-repo control room for the hundred repos now living on your machine, Telegram remote control to start work or approve a step from your phone, and a no-coder mode that builds a product from a description for someone who cannot read a diff.
The key difference: who checks the work, and with what model
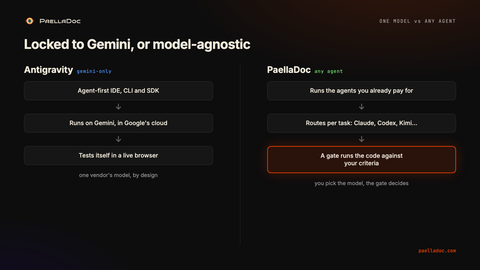
Two things separate these tools, and they are connected.
The first is model lock-in. Antigravity is Gemini. That is the engine, and the speed and the integration come from that. PaellaDoc does not ship a model. You point it at whatever agent you are already paying for, and you can run a hard task across more than one to see who actually solves it.
The second is who grades the work. Antigravity’s Browser Subagent tests the code in Antigravity’s own browser. That is the same agent (or its sibling) deciding whether its own work is correct. It is a much better self-check than a passing compile, and the screenshots are real evidence, but the agent is still both author and examiner. PaellaDoc splits those roles. The gate runs criteria the agent did not write and cannot edit. The work passes because it does what you specified, not because the thing that built it also says it looks right.
A green build, or an agent’s own browser, is not correct
This is not a stylistic preference. We ran a public 210-run benchmark, and a raw agent’s output passed the build but was genuinely wrong 40% of the time. Even the strongest frontier model at maximum effort failed a hard task two times out of three, and failed on different runs each time, so you could not predict it.
A passing build is a weak signal. An agent passing its own browser test is a stronger signal, but it is still the agent’s signal. The gate exists because the only thing that settles it is running the code against a spec the agent did not author. The full write-up is here: a green build is not a correct feature.
Code, or product
Antigravity builds code, fast, and a lot of it. Ninety-three subagents and an OS in twelve hours is a code-production story. PaellaDoc is trying to make the layer above that first-class. The PRD, the epics, the stories, the criteria are not notes you throw away after the build. They are .paella artifacts, versioned and diffable, and the community extends them through an open SDK with four kinds of packs: method packs (the methodology), stack packs (your tech stack), design packs (theming and design tokens), and validator packs (the gates themselves). You end up with product you can review and reuse, not just a folder that compiled.
PaellaDoc does not replace your agent, and it does not replace Gemini
To be clear about the overlap: PaellaDoc is not an Antigravity competitor in the way two IDEs compete. Antigravity is a closed loop, Gemini drives it, Gemini’s browser checks it, Google’s cloud runs it. PaellaDoc is the outer loop around whatever agent you choose. If you wanted Gemini in that loop you would bring it as the CLI agent and PaellaDoc would orchestrate the worktree and run the gate over its diff. PaellaDoc is the harness and the verification, not the model.
What we share
Plenty. Both run autonomous agents that plan, write, and exercise code rather than just autocomplete it. Both run subagents and background tasks. Both believe the agent should test what it built, not hand you an untested diff. And on most axes that decide adoption, Google is ahead: maturity, funding, polish, raw Gemini speed, the enterprise path, and a live-browser self-test that is, on its own terms, very good. PaellaDoc is early and built by one person. I am not going to dress that up.
Comparison
| Capability | Antigravity | PaellaDoc |
|---|---|---|
| Autonomous agents plan, write, and test code | Yes | Yes |
| Parallel subagents and background tasks | Yes | Yes |
| Model choice | Gemini only | Any agent (Claude Code, Codex, Kimi, any CLI) |
| Runs locally on your machine | Cloud / Google account | Local-first, isolated git worktrees |
| Who decides “done” | The agent, via its own browser test | A gate running acceptance criteria the agent did not write |
| Public benchmark on verification | Not published | Yes, 210-run, results linked |
| Product artifacts (PRD, epics, stories, criteria) | Code-focused | Versioned, comparable .paella artifacts |
| Extensible via open packs (method, stack, design, validator) | No | Yes, open SDK |
| Reverse intake of an existing repo | Limited | Yes, reconstructs product context |
| No-coder mode (product from a description) | No | Yes |
| Maturity, funding, scale, polish | Ahead | Early, solo-built |
Who each is for
Antigravity is for teams already on Google cloud and Gemini who want maximum autonomous output and trust an agent to plan, build, and self-verify inside one integrated environment. If you want speed and scale and you are happy in Google’s world, it is a serious tool with a company behind it.
PaellaDoc is for people who do not want to be locked to one model, who keep many repos on one machine, and who want the thing that decides “done” to be a spec they wrote, not the agent’s opinion of its own browser test. It is also for the no-coder who needs a real product from a description, with a gate standing between them and a build that merely compiled.
It is not that one is better. They are different jobs. Antigravity bets that one fast model, grading itself, deployed at Google’s scale, is enough. PaellaDoc bets that the model should be yours and the gate should be independent of it. See the rest of the comparisons at /compare/.