
Esto no es Claude Code contra PaellaDoc. PaellaDoc ejecuta Claude Code. Así que la pregunta de verdad no es cuál eliges, sino qué cambia cuando ese mismo Claude Code corre dentro de PaellaDoc en lugar de directo en tu terminal. Por su cuenta, tú le das el prompt, lees el diff, decides si está bien, un repo cada vez, en tu teclado. Dentro de PaellaDoc, ese mismo agente corre en un worktree aislado, su salida tiene que pasar un gate que él no controla, y el trabajo queda como un artefacto de producto versionado que luego puedes comparar.
Qué hace Claude Code
Claude Code es el agente de programación por línea de comandos de Anthropic. Lo lanzas en tu terminal, lee tu repo, planifica, edita archivos, ejecuta comandos e itera usando los modelos Claude. Es muy bueno en lo esencial: escribir y editar código. Mantiene el contexto de un codebase entero, puede correr tus tests y reaccionar a lo que imprimen, y no te estorba mientras trabaja. Para el acto de producir un cambio es de las mejores herramientas que hay hoy, y PaellaDoc no intenta hacer ese trabajo mejor. Se lo entrega a Claude Code.
Para lo que Claude Code está pensado es para producir un resultado que tú luego juzgas. El gate eres tú. Lees el diff, abres la app, decides si de verdad hizo lo que pediste. Eso funciona bien cuando estás en el teclado, mirando, en un solo repo, con tiempo para revisar. Es la parte que se adelgaza cuando hay diez tareas, cien repos, o alguien al otro lado que no sabe leer un diff.
Qué hace PaellaDoc
PaellaDoc es una capa local que se sitúa alrededor del agente. Ejecuta Claude Code (o Codex, o Kimi, o cualquier agente CLI) en un worktree de git aislado en tu máquina, agnóstico al modelo, con tu propia suscripción. Ahí pasan tres cosas que no pasan cuando corres el agente solo.
Primera, el gate de ejecución. Antes de que una tarea pueda llegar a hecho, PaellaDoc corre el código resultante contra unos criterios de aceptación que escribiste antes. No un check de build, ni “los tests que escribió el agente están en verde”. Una ejecución independiente del comportamiento real contra la especificación. Si no pasa, no está hecho, por muy seguro que estuviera el agente.
Segunda, el trabajo se vuelve producto. Los criterios de aceptación, las historias de usuario, las épicas, el PRD, viven como artefactos .paella versionados que puedes diffear, comparar y reutilizar. Haces producto, no solo código.
Tercera, alcance. Esa misma ejecución del agente es una de varias que puedes enrutar por tarea, la puede dirigir un no-coder que describe lo que quiere, y puedes lanzarla, mirar un gate o aprobar un paso desde Telegram, en cada repo de tu máquina desde una sola sala de control.
La diferencia clave: quién decide el “hecho”
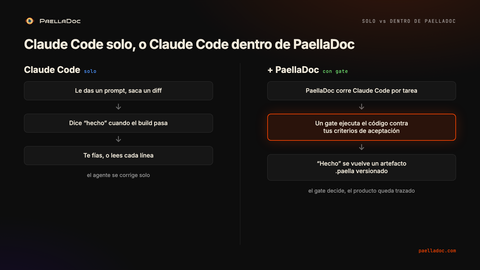
Cuando corres Claude Code por tu cuenta, el hecho lo decides tú. Eres fiable hasta que te cansas, o vas con prisa, o es el tercer repo de la tarde y el diff parece razonable. Cuando Claude Code corre dentro de PaellaDoc, el hecho lo decide un gate de ejecución independiente, y lo decide igual cada vez, contra criterios escritos antes de que el agente viera la tarea. La seguridad del agente no cuenta. Que el build pase no lo cierra. La feature tiene que hacer de verdad lo que toca.
Ese es todo el cambio. Mismo modelo, misma calidad escribiendo código, pero el juicio de si el trabajo está correcto se baja de tus hombros y se pasa a un check repetible que ejecuta el código.
Tenemos números de por qué importa. En un benchmark público de 210 ejecuciones, la salida de un agente en crudo pasaba el build pero estaba genuinamente mal alrededor del 40% de las veces. Incluso el modelo frontier más fuerte a máximo esfuerzo falló una tarea difícil dos de cada tres veces, y falló en ejecuciones distintas cada vez, así que no podías predecir cuál intento sería el malo. El análisis completo está aquí: un build en verde no es una feature correcta. El gate existe porque que el agente sea bueno escribiendo código no significa que el código haga lo que pediste.
Código, o producto
Corre un agente solo y obtienes un diff. Buenos diffs, a menudo. Pero los requisitos, los criterios de aceptación, el razonamiento detrás de una feature, eso vive en tu cabeza o en un log de chat que se pierde hacia arriba. PaellaDoc lo deja por escrito como artefactos de primera clase. Un method pack define cómo trabajas, un stack pack lleva tus decisiones técnicas, un design pack guarda tus tokens y theming, un validator pack es el propio gate. La comunidad los construye y los comparte a través de un SDK abierto, y están versionados, así que el contexto de producto sobrevive a la sesión que lo creó. PaellaDoc también hace intake inverso: apúntalo a un repo existente y lee el código para reconstruir el contexto de producto que nunca se escribió.
PaellaDoc no sustituye a Claude Code, lo ejecuta
Esta es la parte que conviene dejar clara. No hay disyuntiva. PaellaDoc no es una alternativa a Claude Code, es un sitio donde correr Claude Code con un gate alrededor y una capa de producto debajo. Si Claude Code saca un modelo mejor mañana, PaellaDoc se beneficia el mismo día, porque es el agente el que escribe. Conservas tu suscripción, conservas el agente que te gusta, y añades el aislamiento del worktree, la verificación independiente y los artefactos. Claude Code sigue siendo excelente en su trabajo. PaellaDoc solo deja de ser tú en el momento en que aterriza el diff.
Qué compartimos
Los dos corren agentes de programación reales sobre repos reales, en local, en tu propia máquina y con tu propio acceso al modelo. Los dos respetan que el agente debe ser quien escribe. Y para ser claros sobre dónde Claude Code va por delante: es un producto maduro, financiado y pulido de Anthropic, con el equipo de ingeniería y de modelos detrás. PaellaDoc está empezando, lo construye un fundador en solitario, áspero donde Claude Code es suave. Si lo que quieres ahora mismo es la experiencia de agente más refinada en el teclado, esa es Claude Code, y PaellaDoc la ejecuta precisamente para que no tengas que renunciar a ella.
| Capacidad | Claude Code | PaellaDoc |
|---|---|---|
| Escribe y edita código con un modelo frontier | Sí | Ejecuta Claude Code para esto |
| Corre en local con tu propia suscripción | Sí | Sí |
| Lee un repo existente para contexto | Sí | Sí (más intake inverso de producto) |
| Gate de ejecución independiente vs criterios de aceptación | No (juzgas el diff) | Sí |
| ”Hecho” decidido ejecutando el código, no por un build en verde | No | Sí |
| Artefactos de producto versionados (PRD, épicas, historias, AC) | No | Sí (.paella) |
| Worktree de git aislado por tarea | Manual | Sí, automático |
| Enrutar varios agentes por tarea | No (un solo agente) | Sí (Claude Code, Codex, Kimi, cualquier CLI) |
| Modo no-coder (construir desde una descripción) | No | Sí |
| Control remoto por Telegram | No | Sí |
| Sala de control multi-repo | No | Sí |
| Madurez de producto, pulido, financiación, escala | Por delante | Empezando, fundador en solitario |
Para quién es cada uno
Usa Claude Code por su cuenta cuando eres un desarrollador en tu teclado, en un repo que conoces, y vas a ser tú quien lea el diff y abra la app. Es rápido, es bueno, y el bucle de prompt, leer, aceptar es exactamente para lo que está hecho. Para eso no necesitas nada alrededor.
Tira de PaellaDoc cuando dejas de poder ser tú el gate. Cuando hay demasiadas tareas o demasiados repos para revisar cada uno a mano. Cuando alguien que no programa necesita shipear algo y no sabe leer un diff. Cuando quieres que el producto, los criterios y los artefactos, sobrevivan al chat. Cuando “compiló” no basta y necesitas “hace lo que toca”, verificado por algo distinto del agente que lo escribió. Mira el hub de comparativas completo para ver cómo encaja frente a otras herramientas.
PaellaDoc no es mejor que Claude Code. Está haciendo un trabajo distinto. Claude Code escribe el código, y lo escribe bien. PaellaDoc corre ese código en un sandbox, lo contrasta con lo que de verdad pediste, y mantiene el producto a su alrededor. No estás eligiendo entre los dos. Estás decidiendo si el agente corre solo, o corre con un gate.