
Construyo una herramienta que inyecta contexto en un agente de código. Así que lo útil que puedo hacer es enseñarte dónde eso NO ayuda, con números.
He corrido 100+ ejecuciones controladas contra un backend de producción real y privado (unas 32.000 unidades de código indexadas), con cuatro modelos (uno barato, Sonnet; uno de frontera a dos niveles de esfuerzo, Opus; y el router auto, opusplan) y cuatro dificultades. Todo lo de abajo está medido en Claude Code. El mecanismo generaliza a cualquier agente de código; los números son de Claude Code, y lo digo explícito. Esto es exploratorio: un objetivo privado, sin réplica pública todavía, tres repeticiones por celda, con varianza real.
¿Cómo se prueba si el contexto ayuda a un agente de código?
Tres brazos por tarea, cambiando una sola cosa cada vez:
- a pelo: el agente con todas sus herramientas y solo el enunciado. La línea base sin mutilar.
- pack: lo mismo, más un paquete de contexto inyectado en el prompt: los ficheros, símbolos y fragmentos relevantes, ya localizados. La única diferencia frente a a pelo.
- pack-hard: el paquete, pero se bloquean las herramientas de búsqueda del agente (grep, glob, find) y se topan los turnos, para forzar que se apoye en el paquete.
Un “paquete de contexto” aquí es la salida observable: lo que PaellaDoc pone delante del agente. Cómo se construye no es el tema de esta pieza. Lo que le hace al run, sí.
Cuatro dificultades, todas con verdad-de-terreno verificable: localizar una función concreta (fácil), explicar cómo se computa una métrica de negocio entre varios ficheros (media), trazar un flujo end-to-end a través de varios servicios (difícil), e implementar una feature nueva y cablearla (edit). El ancla de coste es el gasto que reporta el propio agente, que precia bien tokens cacheados frente a nuevos y sub-agentes de distinto modelo. La calidad es cobertura sobre una lista de verdad-de-terreno de símbolos y ficheros que la respuesta correcta debe nombrar. Cada run ocurre en un git worktree desechable, así que las herramientas nunca tocan el repo real.
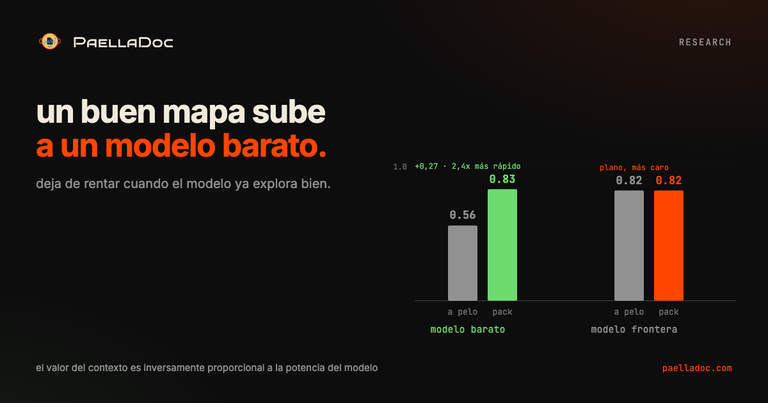
¿Un paquete de contexto hace a un modelo barato tan bueno como uno de frontera?
Para leer y entender el codebase, sí, y ese es el titular.
| Lectura (media de 3 tareas) | Coste | Calidad | Tiempo |
|---|---|---|---|
| Modelo barato, a pelo | $0.26 | 0.56 | 174s |
| Modelo barato, pack | $0.24 | 0.83 | 73s |
| Modelo frontera, a pelo | $0.66 | 0.82 | 193s |
| Modelo frontera, pack | $0.90 | 0.82 | 86s |
Un modelo barato con un buen mapa ha alcanzado la calidad de un modelo de frontera en libertad, al mismo coste o menor, y más del doble de rápido. El paquete es un igualador: sube el suelo de un modelo débil.
El mecanismo no es inteligencia extra. Sin el paquete, el agente lanza sub-agentes baratos a explorar (lo ha hecho en unas 18 de 27 ejecuciones de lectura). Con el paquete eso casi desaparece (unas 4 de 27) y usa más o menos la mitad de tokens. El paquete sustituye trabajo, no añade cerebro.
¿Por qué el contexto deja de ayudar a los mejores modelos?
Mira otra vez la fila de frontera: calidad con pack 0.82, igual que a pelo, pero el coste ha subido. Todo el experimento se reduce a una línea, y va en mi contra:
El valor del contexto es inversamente proporcional a la potencia del modelo.
Un modelo de frontera ya explora bien solo. Darle un mapa que no necesitaba le añade coste y le ahorra un trabajo que hacía encantado. El paquete renta más justo donde el modelo es más débil, y menos donde el modelo es más fuerte.
¿Demasiado contexto puede empeorar a un modelo fuerte?
Sí, y es el hallazgo que menos quería publicar. En la tarea más dura, trazar un flujo de punta a punta, un paquete de una sola consulta es parcial por naturaleza. Un modelo fuerte que habría trazado todo en libertad se fía del mapa parcial y se deja partes.
| Tarea más dura, calidad | a pelo | pack | pack-hard |
|---|---|---|---|
| Modelo barato | 0.20 | 0.50 | 0.67 |
| Modelo frontera | 0.83 | 0.47 | 0.50 |
En la difícil, el paquete rescata al barato (0.20 a 0.67) y ciega al fuerte (0.83 a 0.47). Caveat: n=3 por celda, la varianza es alta, y los dos esfuerzos de frontera van en direcciones opuestas (uno empeora, el otro mejora), así que el cegado es real pero ruidoso. No sobreinterpretes una celda suelta.
¿Un modelo de frontera escribe mejor código que uno barato?
Para escribir la feature, no, y lo he comprobado ejecutando el código. La primera versión de esto usaba una métrica débil: ¿ha editado los ficheros correctos y ha nombrado los símbolos correctos? Un desconfiado diría, con razón, que eso prueba intención, no un algoritmo que funciona. Así que la he sustituido por verificación objetiva.
La tarea era una función pura y estándar, calculate_max_drawdown(daily_values) -> float: la mayor caída pico-a-valle de una serie como fracción no positiva (por ejemplo -0.25 para una caída del 25 %, 0.0 si nunca cae por debajo de su máximo móvil). La función y los casos de prueba son de diseño propio, no código del repo objetivo, así que son del todo publicables.
¿Cómo sabes que el código del modelo barato funciona de verdad?
He extraído la función del git diff de las 28 ejecuciones de edición y he corrido cada una contra 7 casos canónicos:
| Serie de entrada | Esperado | Por qué |
|---|---|---|
[100, 50] |
-0.50 | caída simple del 50 % |
[100, 110, 90] |
-0.1818 | valle relativo al pico |
[100, 80, 120, 60] |
-0.50 | la mayor de dos caídas |
[50, 100, 75] |
-0.25 | caída tras nuevo máximo |
[100, 100, 100] |
0.0 | sin caídas |
[100, 110, 120] |
0.0 | monótona creciente |
[100] |
0.0 | serie demasiado corta |
Una implementación cuenta como correcta solo si pasa los 7 (tolerancia 0,02). Las 28 implementaciones pasan 7 de 7. Sonnet incluido.
| Modelo | 7/7 correctas |
|---|---|
| Sonnet | 12 / 12 |
| Auto (opusplan) | 9 / 9 |
| Opus, esfuerzo alto | 5 / 5 |
| Opus, esfuerzo máx | 2 / 2 |
| Total | 28 / 28 |
Así que la única diferencia que queda es el dinero. Mismo resultado verificado como correcto, 5-6× el coste:
| Modelo (verificado 7/7) | Coste |
|---|---|
| Sonnet + PaellaDoc | $0.44 |
| Sonnet, a pelo | $0.56 |
| Auto (opusplan) | $0.50 |
| Opus, esfuerzo alto | $2.49 |
| Opus, esfuerzo máx | $2.84 |
El modelo de frontera no ha producido un resultado mejor. Ha producido el mismo resultado correcto, 5-6× más caro, y puedes replicar la comprobación: los casos están arriba, la función es estándar.
Esto verifica la función, lo sustantivo de la feature. No corre la suite de tests completa del repo (el cableado de la función en el pipeline), porque el objetivo es privado y su entorno no se puede publicar. La verificación end-to-end con pytest llegará con la réplica open-source. n=2 a 12 por modelo; el patrón “todas correctas” es firme en lo ejecutado.
¿El contexto hace más rápido a un agente de código?
Recorta el tiempo de pared eliminando exploración, ~1,8× de media y hasta 2,4× en un modelo barato. Es un eje distinto del “fast mode” (que acelera la generación de tokens). Se multiplican: el speedup de aquí viene de hacer menos trabajo, no de generar más rápido, así que los dos se acumulan. No los he medido juntos, así que trata el número combinado como aritmética, no como medición.
| Velocidad lectura | a pelo | pack | speedup |
|---|---|---|---|
| Modelo barato | 174s | 73s | 2,37× |
| Modelo frontera | 193s | 86s | 2,25× |
| Global | 184s | 100s | 1,84× |
¿El router auto de Claude Code te da Opus en CI?
No, y esto conviene saberlo. El router automático (opusplan) debería elegir el modelo fuerte cuando la tarea lo merece. En 19 ejecuciones headless (--print, el camino que usan CI y los SDK), ha elegido el modelo fuerte cero veces. Solo escala en plan-mode interactivo. En automatización, auto significa modelo barato. Si tu modelo mental es “lo pongo en auto y tengo lo mejor de cada uno”, eso no es lo que corre en tu pipeline.
¿Conviene bloquear las herramientas de búsqueda del agente para forzarlo a usar el contexto?
Sale el tiro por la culata. Bloquear grep y glob (pack-hard) no ha hecho los runs más rápidos (~1,0×) y a veces ha bajado la calidad, porque el agente rodea el bloqueo con sub-agentes: más tokens, más varianza. La lección es la contraria a forzar. Inyecta contexto, y deja las herramientas en paz.
¿Esto ayuda a los modelos locales, no de frontera?
Aquí es donde creo que más importa, y tengo que ir con cuidado, porque no lo he medido aquí. El experimento ha corrido sobre modelos cloud, usando uno barato y uno de frontera como los dos extremos de un eje de capacidad. El resultado más claro ha sido el igualador: un paquete de contexto sube a un modelo barato hasta calidad de frontera, al mismo coste y el doble de rápido.
Un modelo local, de los que corres en tu máquina sin nube, está aún más abajo en ese eje que el modelo barato cloud. La ley inversa dice que el contexto ayuda más justo ahí. Así que la extrapolación razonable es que un buen mapa debería ayudar a un modelo local más, no menos. Ese es el siguiente test: el mismo protocolo contra un modelo local, en un escritorio, offline.
Si se sostiene, aterriza en la parte de PaellaDoc que nunca ha sido sobre ahorrarle dinero a un usuario de frontera. Es sobre hacer que un modelo no de frontera, local, privado, sea lo bastante bueno para trabajar sobre un codebase real. Esa es la apuesta de soberanía: tu código y tu modelo en tu máquina, con un mapa lo bastante bueno para no tener que alquilar inteligencia de frontera para obtener una respuesta fiable.
Lo que este experimento no muestra
- Un objetivo único privado, así que sin réplica pública todavía. Una versión reproducible sobre un repo open-source es el siguiente paso.
- La calidad es un proxy de cobertura de palabras clave sobre verdad-de-terreno. La tarea fácil satura en 1.0; falta un pase de juicio LLM o humano más fino sobre las respuestas guardadas. (El edit sí está verificado por ejecución.)
- n=3 por celda significa varianza real, peor en la tarea dura. Las celdas de lectura del modelo barato y el de frontera son la parte sólida (n=9); las cifras de edición y router auto son preliminares y marcadas como tal, salvo el hecho “el router auto ha usado el modelo fuerte 0 de 19 veces”, que es firme.
- El eje barato-frente-a-frontera ha usado modelos cloud. El caso del modelo local es una extrapolación del efecto igualador, no una medición, y es el siguiente run.
- Medido solo en Claude Code. El mecanismo generaliza, los números no.
¿Para quién es un modelo de frontera?
Un modelo de frontera es la herramienta correcta cuando no puedes traer el mapa. Eso cubre a mucha gente: cualquiera menos técnico, cualquiera que no quiera hacer context engineering, cualquiera para quien la inteligencia bruta sea el camino más barato a una buena respuesta. Los labs hacen bien en construir y tarificar para eso, y la audiencia crece.
Un dev que entiende el bucle agéntico no es esa audiencia. Si puedes traer el contexto, dejas de necesitar alquilar la inteligencia que compensa no tenerlo. El benchmark es solo el recibo: el mismo código correcto, una fracción del coste, en el momento en que traes el mapa tú.
Ese es el sentido de entender cómo funciona el desarrollo agéntico en vez de tratarlo como una caja negra. La prima de un modelo de frontera es, en parte, una prima por no traer contexto, y puedes salirte de ella. PaellaDoc es una forma de traer el mapa: tu propio código, en tu máquina, para que hasta un modelo barato o local tenga con qué trabajar.
La frase para llevarte
Un buen mapa del repo hace a un modelo barato rendir como uno caro, y unas dos veces más rápido, y deja de rentar en el momento en que el modelo ya explora bien solo. El contexto no es una mejora gratis que enchufas a todo. Es una palanca que es más fuerte donde el modelo es más débil, y puede cortar al revés en un modelo fuerte y una tarea amplia.
Esa es la apuesta detrás de PaellaDoc: no un modelo más listo, un mejor mapa de tu propio código, en tu máquina, lo bastante bueno para que hasta un modelo local haga trabajo real sobre un repo real. La parte interesante nunca ha sido “¿ayuda el contexto?”, ha sido “¿dónde sí, y dónde no?”.
PaellaDoc es local-first y gratis. Corre tu agente contra tu propio repo, sin nube y sin cuenta.
Esto va al lado del resto de lo que mido en abierto: un build verde no es una feature correcta y los agentes de largo recorrido necesitan un runtime, no un modelo más grande.