
Esto es un benchmark exploratorio, y voy a ser preciso con lo que muestra y con lo que no. Los datos completos, el harness y el límite de claim están en el repositorio abierto.
El montaje: una maratón, no una tarea suelta
Casi todos los benchmarks de código le dan al agente una tarea y puntúan el resultado. Pero ahí no es donde se rompe el trabajo de largo recorrido.
Así que este es acumulativo. Cuatro episodios, en secuencia. Cada episodio añade comportamiento nuevo, pero los gates ocultos de todos los episodios anteriores siguen activos: idempotencia, privacidad, replay determinista, checkpoint y resume, eventos tardíos, paths negativos. El agente tiene que mantener todo eso en verde mientras añade lo siguiente. La nota final es cuántos gates siguen pasando al terminar.
Esa es la forma real del trabajo largo. Nunca añades sobre una página en blanco. Añades sobre un sistema que ya tiene invariantes, y la pregunta es si las rompes según creces.
Qué pasó con Haiku/low
Tres brazos, mismo modelo y esfuerzo, cuatro réplicas completas (una quinta quedó parcial y se excluye de los claims).
| Brazo | Pasadas completas | Nota final media | Intentos de recuperación |
|---|---|---|---|
| Claude Code (instrucciones fuertes) | 0/4 | 66,67% | 0 |
| Claude Code (skill local de recovery) | 0/4 | 66,67% | 0 |
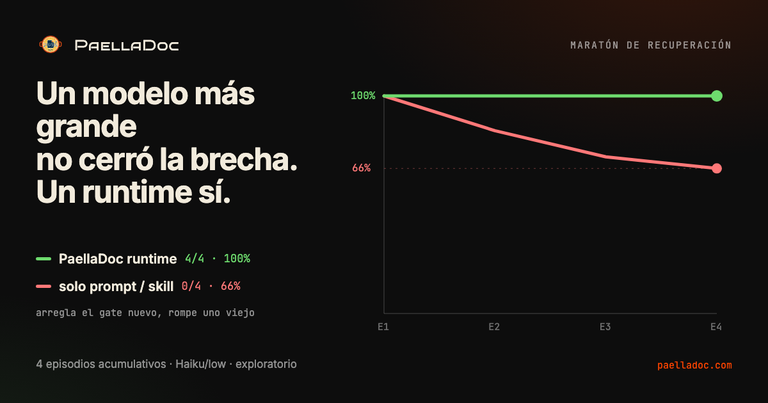
| PaellaDoc runtime | 4/4 | 100% | ~5 |
Lee el 66,67% con cuidado, porque el número solo esconde la historia. No es bajo rendimiento al azar. Los dos brazos de Claude Code se quedaron clavados en exactamente dos tercios, cada vez, por la misma razón: arreglaban el requisito nuevo y rompían un invariante viejo. Añade el manejo de eventos tardíos, se carga la idempotencia. Añade el path negativo, pierde el replay determinista. Nunca se recuperaron, porque nada les decía que habían regresado.
El runtime de PaellaDoc llegó al 100% en las cuatro. No porque el modelo fuera más listo, era el mismo Haiku al mismo esfuerzo. Porque cuando un gate se ponía en rojo, el runtime lo detectaba, re-puntuaba y recuperaba antes de seguir.
Un modelo más grande no lo arregló
La objeción obvia: a lo mejor el baseline solo necesita un modelo más fuerte. Así que corrí los mismos brazos de prompt y de skill en Sonnet/low y Opus/low.
Los dos fallaron al 66,67%, igual que Haiku. n=1 cada uno, así que tómalo como un control direccional, no como prueba. Pero apunta en la misma dirección: la brecha aquí no es inteligencia bruta. Un modelo más capaz sigue arreglando lo nuevo y rompiendo lo viejo si nada gobierna la recuperación.
La parte que va en mi contra
Aquí está el resultado que más importa, y va en mi contra.
Le di a Claude Code un harness casero: la skill de recovery más un loop externo de reintentos con feedback del scorer. Sin cápsula de PaellaDoc, sin runtime, solo re-puntuar y reintentar. En una ejecución Haiku/low n=1, pasó. 100%, en tres intentos de recuperación.
Así que el comportamiento de recuperación no es magia exclusiva, y la ventaja no es un prompt secreto. Un equipo puede montarse un harness de reintentos y llegar. Lo que el benchmark muestra de verdad es más estrecho: el valor está en productizar y gobernar ese loop de recuperación para que cada equipo no tenga que montar y mantener el suyo.
Y en coste: PaellaDoc no es más barato aquí. En la comparación auditada de una ejecución usó 9,52M tokens frente a 8,54M del harness de feedback-retry, algo más, mismo orden de magnitud. No voy a cantar una victoria de coste que estos datos no sostienen.
Lo que voy a afirmar y lo que no
Voy a afirmar esto:
PaellaDoc no hace a Claude más listo. Convierte Claude Code en un runtime de entrega recuperable, auditable y gobernado para trabajo de largo recorrido: estado en cápsula, loop de re-score, contabilidad de uso, ledger de evidencia y continuidad entre episodios.
La ventaja es el loop de recuperación gobernado. Un prompt mejor no te lleva ahí, y un modelo más grande tampoco. El trabajo agéntico de largo recorrido necesita un runtime.
No voy a afirmar que PaellaDoc sea más barato, que gane a todos los setups de Claude Code, que Claude Code no pueda hacer esto, ni que un benchmark duro pruebe un resultado general. El control más justo y más fuerte es el harness de feedback-retry, y pasó. Para convertir “gana a un prompt” en “productiza la recuperación mejor que un harness casero” hace falta una corrida auditada n≥5 de PaellaDoc contra feedback-retry, mismo modelo, mismos gates, misma auditoría de tokens. Ese estudio es el siguiente, y se publicará igual: en abierto, con los caveats por delante.
Es el mismo argumento que el resto de lo que construyo, ahora medido: un build en verde no es una feature correcta, un modelo más grande no es la capa de decisión, tú eres el runtime sosteniendo el bucle de recuperación a mano, y la recuperación merece ser un flujo de primera en vez de heroísmo a las 2am.
Todo, incluida la réplica parcial y la auditoría de tokens, está en el repositorio.