
Superset and PaellaDoc sit on the same layer. Both run many coding agents in isolated git worktrees, both are agent-agnostic, both let you keep your own subscription. The split is what happens when an agent says it is finished. Superset puts that diff in front of you, fast and at scale, and you decide by looking. PaellaDoc decides by running the code against acceptance criteria you wrote first. That is the whole conversation, and it is worth being concrete about it.
What Superset does
Superset, by Superset Inc., is a YC-backed Mac desktop app billed as the code editor for AI agents. It runs many agents in parallel, from ten to a hundred or more, each in its own isolated git worktree, and it works with Claude Code, Cursor, Codex, Copilot, Gemini and others. The thing it does well is scale and review. You can fan out a lot of agents, watch their work land, and review diffs quickly without them stepping on each other.
It is also strong where a code editor should be strong. Open any agent’s work directly in VS Code, Cursor, Xcode, JetBrains or a terminal. Manage a wall of terminals. Port forwarding. Cloud workspaces when you want to move off your machine. It is free to download for Mac with premium tiers on top. It is polished, it scales agents in a way that is genuinely impressive to watch, and the IDE integration is better than what PaellaDoc has. Concede that up front.
What PaellaDoc does
PaellaDoc runs the same kind of fleet, agents in isolated worktrees on your machine, model-agnostic, bring your own subscription. The difference starts at the word “done.”
PaellaDoc has an execution gate. Before an agent starts, you write acceptance criteria. When the agent says it is finished, PaellaDoc runs the code against those criteria. A green build does not count as done. The gate either passes because the behavior is there, or it fails and hands back what failed. You do not have to be watching for this to be true.
Around that gate sits a product layer. Your work becomes versioned .paella artifacts, a PRD, epics, user stories, acceptance criteria, comparable across runs and across the team. There is a No-coder mode that builds a whole product from a plain description, for someone who cannot read a diff. There is reverse intake that reads an existing repo and reconstructs its product context. There is Telegram control to start work, check a gate or approve a step from your phone. And there is a multi-repo control room, because in the AI era you have a hundred repos on your machine and you need one place to open, organize and tag them all.
The key difference: review at scale, or verify
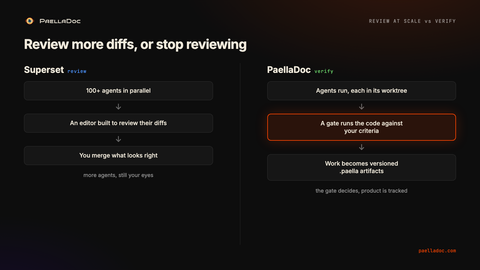
Superset makes you faster at the thing you already do, looking at diffs. More agents, more diffs, less friction between them, all in one window. The decision stays with your eyes. That is a real job and Superset does it well.
PaellaDoc moves the decision off your eyes. The criteria are written first, the gate runs the code, and the verdict comes from execution, not from how the diff reads. The reason this matters is that a diff that looks right and a diff that is right are not the same diff, and at scale you cannot tell them apart by reading faster. Reviewing fifty diffs that all look plausible is still fifty judgment calls under time pressure.
This is where the benchmark comes in. Across 210 runs, a raw agent’s output passed the build but was genuinely wrong 40% of the time. Even the strongest frontier model at maximum effort failed a hard task two times out of three, failing on different runs each time. Reading the diff would not have caught that, because the build was green and the code looked fine. That is the trap review-at-scale shares with any tool that ends at the diff. We wrote it up here: a green build is not a correct feature.
Code, or product
Superset calls itself the code editor for AI agents, and the name is exact. It operates at the code level, the diff, the worktree, the terminal, the IDE. PaellaDoc operates one level up, at the product. The .paella artifacts are the product made first-class, and they are built on an open SDK. The community ships four kinds of packs: method packs for the methodology, stack packs for your tech stack, design packs for theming and design tokens, validator packs for the gates themselves. You assemble the packs that fit your work and they version and compare like code. The point is to make product, not just to make code move through worktrees faster.
PaellaDoc does not replace your editor
Worth being clear, because Superset and PaellaDoc both touch the editor question. Superset is an IDE-grade place to run and review agents. PaellaDoc is not trying to be your editor and it is not trying to replace Superset’s review surface. If diff review at scale across dozens of agents is what you want, that is Superset’s home turf and it is better at it. PaellaDoc adds the gate and the product layer on top of agent runs. The two bets do not occupy the same square.
What we share
A lot. Parallel agents in isolated git worktrees. Agent-agnostic, so you pick the model. Local-first on a Mac with your own subscription. Free to start. And Superset is ahead on the things that take time and a team to build: it is more polished, it scales agents further today, its IDE integration is deeper, and it has YC backing behind it. PaellaDoc is early and built by a solo founder. Those are real differences and they cut in Superset’s favor.
| Superset | PaellaDoc | |
|---|---|---|
| Parallel agents in isolated worktrees | Yes | Yes |
| Agent-agnostic (Claude Code, Codex, others) | Yes | Yes |
| Local-first, bring your own subscription | Yes | Yes |
| Diff viewing and review at scale | Yes, dozens to 100+ | Basic |
| IDE integration (VS Code, Cursor, Xcode, JetBrains) | Yes, deep | Limited |
| Execution gate (done = code runs against criteria) | No, review by eye | Yes |
Product layer (.paella PRD, epics, stories, criteria) | No | Yes |
| Open SDK packs (method, stack, design, validator) | No | Yes |
| No-coder mode (product from a description) | No | Yes |
| Reverse intake of an existing repo | No | Yes |
| Telegram remote control | No | Yes |
| Maturity, polish, scale, funding | Ahead | Early, solo founder |
Who each is for
Pick Superset if your bottleneck is reviewing more agent work, faster, and you live in an IDE. If you are running a wall of agents, want to open any of their worktrees in your editor in one click, manage terminals and ports, and review diffs quickly, Superset is built for exactly that and it is good at it.
Pick PaellaDoc if you want “done” decided by running the code, not by reading the diff, and if you want the work to exist as product, versioned .paella artifacts you and your team can compare, with packs you assemble from an open SDK. It also fits if you need No-coder mode, reverse intake on an existing repo, or remote control from your phone.
PaellaDoc is not better than Superset. It is doing a different job. Superset makes you fast at reviewing agents at scale. PaellaDoc decides done by execution and lifts the work up to product. See the full lineup on the compare hub.