
Both run coding agents in parallel on your Mac, in isolated git worktrees, with whatever models you already pay for. On that, they agree. The difference is one step: when an agent finishes, who decides it’s done, your eyes on the diff, or a gate that runs the code?
What Conductor does
Conductor, by Melty Labs, is a Mac app that runs Claude Code, Codex, and Cursor agents in parallel, each in its own isolated worktree. You see at a glance what each one is doing, then you review the diffs and merge what you want. It adds checkpoints to roll back, spotlight testing to sync changes into your main repo, and a multi-model mode to run two models on the same prompt and compare.
Credit where it’s due. It’s free (you bring your own subscription), it’s polished, and the diff-first review workflow is genuinely well made. For a developer who wants to fan out agents and review the results, Conductor is purpose-built and a pleasure to use.
What PaellaDoc does
PaellaDoc also runs agents locally, in isolated worktrees, model-agnostic, with your own subscription. We share that ground with Conductor, and it’s worth saying plainly. Three things are different:
- It carries a product methodology, not just an agent runner, and it’s extensible through an open SDK. The work becomes first-class, versioned
.paellaartifacts, a PRD, epics, user stories, acceptance criteria, that you can compare and diff. You make product, not just code. - “Done” is decided by an execution gate: the code runs against those acceptance criteria, and a green build doesn’t count.
- There’s a no-coder mode that builds a whole product from a description, for someone who can’t review a diff at all.
The difference that matters: review vs. verify
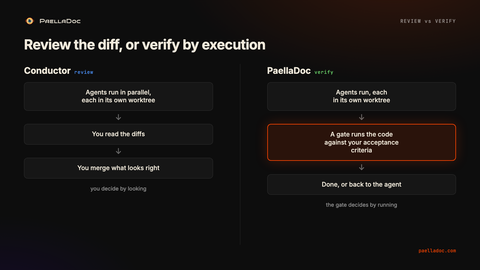
Conductor’s loop is diff-first: the agent produces changes, you read them, you merge. It makes you a faster, better-equipped reviewer. PaellaDoc’s loop is verify-first: the agent produces changes, a gate executes them against criteria the agent didn’t write, and only then is it done.
This isn’t a matter of taste. We measured it. Across 210 runs, a coding agent’s output passed the build but was genuinely wrong 40% of the time, and even the strongest frontier model failed a hard task two out of three times, on different runs each time. A green build is not a correct feature. Reading a diff that looks right is the same trap: looks right and is right are different claims, and on a non-deterministic agent you can’t close the gap by eye.
Conductor’s spotlight testing helps here, it lets you sync changes back and test them. But that’s you running tests by hand, when you remember to, on the runs you choose to look at. The gate runs the criteria on every change, every time, whether you’re watching or not.
Code, or product
This is the bigger gap, and it’s easy to miss. Conductor operates on code: agents, diffs, worktrees, merges. It’s very good at moving code around, and it doesn’t pretend to be more, which is part of why it’s clean.
PaellaDoc operates on product. The unit isn’t a diff, it’s a product artifact: a PRD, an epic, a user story, its acceptance criteria, each a real .paella file that’s versioned, portable, and comparable. You can diff your product spec the way Conductor diffs code, and compare two approaches at the level of intent, not just changed lines.
The whole thing is extensible through an open SDK, and the community can build and share packs of four kinds: method packs for the methodology itself, stack packs for your tech stack, design packs for theming and design tokens, and validator packs for the gates that check the work. None of this has an equivalent in a tool that operates on diffs.
So the line is this. Conductor makes you faster at producing code, and the product is whatever you remember to keep coherent on top. PaellaDoc makes you build the product, with the agents and the code underneath it.
It doesn’t assume you’re sitting at the Mac
Conductor is an app you sit in front of: you watch the agents and review the diffs. PaellaDoc relaxes both assumptions.
Point it at a repository you already have and it does a reverse intake, reading the existing code and reconstructing the product context around it, so you’re not stuck with greenfield. And you can drive it from Telegram: start work, check a gate, approve a step, from your phone, nowhere near the machine. Together with the no-coder mode, that’s three ways it reaches past “a developer at a Mac,” which is exactly who Conductor is built for, and built well for.
One repo, or all of them
Conductor runs agents inside a repository. That’s the unit: a repo, its worktrees, its diffs.
In the AI era you don’t have one repo, you have a hundred, scattered across your machine, half of them half-finished. PaellaDoc opens and organizes them: every project in one place, taggable, with its state visible, the agents, the gates, where each one stands. It’s a control room for all your projects, not a runner inside one of them.
Why this matters more if you can’t read code
Conductor’s whole workflow is built around reading the diff. That’s the right design for a developer. It’s the wrong design for someone who can’t read code at all.
A no-coder has no diff to review, or rather, the diff means nothing to them. Conductor doesn’t serve that person, because its core loop is human review. PaellaDoc’s no-coder mode is built for exactly them: the gate is the review they can’t do themselves.
What we share, so this is fair
Both are local, on your Mac. Both are model-agnostic (Claude, Codex, and more). Both use your own subscription instead of charging per token. Both isolate work in git worktrees. If you want parallel agents with a clean review UX, Conductor does that well, and it’s free, which is hard to argue with.
Side by side
| Conductor | PaellaDoc | |
|---|---|---|
| Local, on your Mac | Yes | Yes |
| Parallel agents in worktrees | Yes | Yes |
| Model-agnostic, your subscription | Yes | Yes |
| Works on | Code (diffs, merges) | Product (PRD, US, AC as .paella artifacts) |
| Deciding “done” | You review the diff | Execution gate vs. criteria |
| Extensible packs via open SDK | No | Method, stack, design, validator packs |
| Reverse intake (rebuild product context from an existing repo) | No | Yes |
| Drive it remotely (Telegram) | No | Yes |
| Manages all your projects (control center, tags) | No (per repo) | Yes |
| For non-coders | No (diff-first) | Yes (no-coder mode) |
| Polish, review UX | Ahead | Earlier |
Who each is for
If you’re a developer who wants to run several agents at once and review their diffs yourself, with a clean, polished UX, Conductor is built for that, and it’s free. Hard to beat for that job.
If you want “done” decided by running the code against criteria instead of by your eyes, or you need a whole product built by someone who can’t review code, that’s where PaellaDoc is different.
It isn’t better, and it isn’t trying to be Conductor. Conductor is a focused tool for running agents and reviewing their code, free and well made. PaellaDoc is the system around the work: the product, the gate, the packs, all your repos, and the people who can’t read a diff. Different jobs, and one of them still works when there’s no one to review.