

People ask if PaellaDoc is an alternative to Codex. It is not. PaellaDoc runs Codex. The real comparison is Codex on its own in your terminal, versus Codex running inside PaellaDoc, where its output has to pass an independent gate before anything is called “done”. Codex is the agent that writes the code. PaellaDoc is the layer that decides whether the code is actually right.
What Codex does
Codex is OpenAI’s command-line coding agent. You point it at a repo, it reads the code, writes and edits files, runs the tests, and iterates until things look green, using OpenAI models. It lives in your terminal or in CI, and it is good at the core loop of turning an instruction into a working change. If you have used it, you know it moves fast and handles a lot of the grind of writing and fixing code.
That is a real strength, and PaellaDoc does not try to reproduce it. Writing code is Codex’s job, and it does it well.
What PaellaDoc does
PaellaDoc is a local-first layer that sits around the agent. It runs Codex (and Claude Code, Kimi, or any CLI agent) in an isolated git worktree on your machine, model-agnostic, on your own subscription. Around that it adds the parts that decide whether the work was any good:
- An execution gate. “Done” is not a green build. Done is the code running against acceptance criteria you wrote first. The gate executes the change in a sandbox and checks it against those criteria. If it does not pass, it does not ship.
- Versioned product artifacts. A PRD, epics, user stories and acceptance criteria become real
.paellafiles in your repo, comparable across runs, built and shared through an open SDK of packs (method, stack, design, validator). - Per-task multi-agent routing. Different tasks can go to different agents. Codex on one, another model on the next, chosen per task instead of locked to one tool.
- A no-coder mode that builds a whole product from a plain description, for someone who cannot read a diff.
- Telegram control to start work, check a gate, or approve a step from your phone.
- A multi-repo control room that opens, organizes and tags the hundred repos you now have on your machine.
The key difference
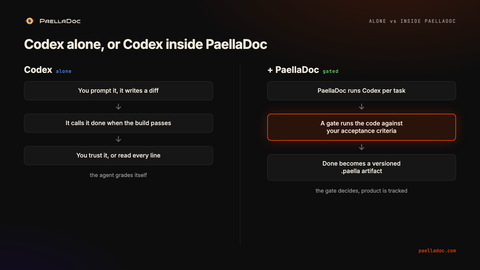
Codex decides it is done when the tests pass and the build is green. PaellaDoc decides it is done when the code does what you specified, checked by running it. Those are not the same thing, and the gap between them is where most of the pain lives. Codex optimizes toward a green run. PaellaDoc treats the green run as a starting point and asks a separate question: does this actually meet the criteria.
This is why the two stack instead of compete. You still want Codex writing the code as fast as it can. You also want something that does not take its word for it.
Why a green build is not enough
We ran a public 210-run benchmark on exactly this. A raw agent’s output passed the build but was genuinely wrong 40% of the time. And the strongest frontier model at max effort still failed a hard task two times out of three, failing on different runs each time. That is the whole argument for an independent gate: the build going green tells you the code compiles and the existing tests are happy, not that the feature is correct. The write-up is here, a green build is not a correct feature. And here is what it looks like live: I gave the Codex desktop app and PaellaDoc the same app to build, asked the Codex app to verify its own work, and only one of them still worked the next day.
Code, or product
Codex produces code. PaellaDoc tries to make you produce product. The methodology, the spec, the acceptance criteria, the decisions, all of it becomes first-class versioned artifacts in .paella, instead of living in a chat history that disappears when you close the terminal. You write the criteria first, the work gets measured against them, and the result is something you can compare, review and reuse. The community builds packs on top: method packs for how you work, stack packs for your tech, design packs for tokens and theming, validator packs for the gates themselves. You make product, not just code.
PaellaDoc does not replace Codex, it runs it
To be very clear: PaellaDoc is not an alternative to Codex. Codex is one of the agents PaellaDoc runs. If you love Codex, keep using Codex. PaellaDoc gives it a worktree to work in, hands it a task with acceptance criteria attached, and then verifies the diff it produces. The frequent question is “does PaellaDoc replace Codex?” and the answer is no, it runs it and checks its work. Anything Codex does well, you keep. What you add is the verification and the product layer it does not have.
What we share
Both run real coding agents against a real repo, locally, on your terminal. Both read existing code and act on it. Both fit into a developer’s normal loop instead of asking you to move your code somewhere else.
And Codex is ahead on the things a big lab does well: it is more mature, more polished, better funded, and backed directly by the models it runs on. PaellaDoc is early and built by a solo founder. If you want the most refined raw-agent experience today, that is Codex, and that is fine, because PaellaDoc runs it.
| Codex | PaellaDoc | |
|---|---|---|
| Runs a coding agent on your repo | Yes | Yes (runs Codex and others) |
| Reads existing code and acts on it | Yes | Yes |
| Local, in your terminal | Yes | Yes |
| Model / agent choice | OpenAI models | Model-agnostic, per-task routing |
| ”Done” decided by an execution gate | No (green build) | Yes (runs your acceptance criteria) |
| Versioned product artifacts (.paella) | No | Yes (PRD, epics, stories, criteria) |
| Open SDK of packs (method/stack/design/validator) | No | Yes |
| No-coder mode | No | Yes |
| Telegram remote control | No | Yes |
| Multi-repo control room | No | Yes |
| Maturity, polish, funding, scale | Ahead | Early, solo founder |
Who each is for
If you are a developer who wants the fastest, most polished agent to write and fix code in your terminal, and you trust yourself to judge whether the result is correct, Codex on its own is a strong choice. It does the core job well and it is backed by a lab.
If you want the code written by an agent but you do not want to take the green build on faith, if you want the work to become versioned product artifacts you can compare and reuse, if you want to route tasks across models or build for someone who cannot read a diff, PaellaDoc is the layer to put around it. And the agent inside that layer can be Codex.
PaellaDoc is not better than Codex. It is doing a different job. Codex writes the code. PaellaDoc decides whether the code is right and turns the work into product. You can see how that framing plays against other tools on the compare hub.