
Durante un tiempo mi setup eran tres terminales. Claude Code en uno, Codex en otro, Kimi cuando alguno saturaba. Funcionaba, como funciona hacer malabares con tres cosas. Luego he empezado a meter tareas reales por ahí y se han visto las grietas.
Un retoque de copy tonto se llevaba el mismo modelo pesado que una migración de base de datos. La mitad de las veces enrutaba algo a un motor que ni siquiera estaba instalado en esa máquina, y me enteraba cuando fallaba. Estaba tomando una decisión de runtime a mano, mal, en cada tarea.
Ahí ha dejado de ser la pregunta el “qué modelo uso”. El modelo no es la unidad de trabajo. La tarea sí.
Un retoque de copy no es una migración
Un cambio de una línea en la UI y una migración de Alembic no son el mismo trabajo. Una puede tirar producción abajo. La otra es cosa de cinco minutos que le puedes dar al modelo más barato que tengas. Manda todo a tu motor más caro y quemas dinero en chorradas. Manda todo al más barato y la migración te explota en la cara.
Así que las preguntas de verdad no van del modelo. Van del trabajo que tienes delante. Qué tipo de tarea es. Qué motor está disponible de verdad en esta máquina o cuenta. Qué coste y qué latencia aceptas. Qué ha pasado la última vez que has corrido algo parecido. Y qué cosa segura ocurre cuando el sistema no puede decidir.
Los CLIs se han vuelto más listos en esto, y conviene ser preciso. Claude Code ya enruta dentro de su propia casa: planifica con Opus y ejecuta con Sonnet, y cae a un modelo más ligero cuando llegas a un límite. Codex sube y baja su esfuerzo de razonamiento solo. Eso es enrutado de verdad, y está bien.
Pero es enrutado dentro de un proveedor. Claude enruta entre modelos de Anthropic. Codex enruta entre modelos de OpenAI. Ninguno va a mandar tu tarea barata a Kimi, tu migración a un modelo frontier y tu trabajo offline a un modelo local, porque ese no es su trabajo. Su trabajo es correr bien su motor. Y ninguno responde a las preguntas de producto: disponibilidad entre motores, coste entre proveedores, qué ha funcionado en tu repo, qué cosa segura pasa cuando la llamada falla. Para trabajo puntual, el enrutado de casa sobra. Deja de bastar en cuanto quieres un producto entre motores en vez de una sola herramienta buena.
Un motor es una palanca. Sigue haciendo falta la mano.
PaellaDoc no envuelve un CLI y lo llama otro chat. Trata a Claude, Codex, Kimi, Gemini, cualquier modelo open source a través de Ollama o cualquier CLI al que lo apuntes como una flota de motores intercambiables bajo un mismo contrato. Cuando entra una tarea, un router elige el motor y el perfil para ese trabajo: cheap, balanced, strong o frontier.
Esa es la diferencia en una línea. Un CLI es una palanca. PaellaDoc es la capa que decide cuándo, cómo y por qué tirar de cada una.
La semana que retiraron un modelo
Un ejemplo real, de la misma semana en que escribo esto. Anthropic lanzó Fable 5 un lunes. Para el jueves, una orden de control de exportaciones de EEUU les obligó a desactivarlo y a cortar el acceso a cualquier ciudadano extranjero, dentro o fuera de Estados Unidos. Yo trabajo desde Valencia. Si mi producto hubiera estado atado a ese único modelo, el jueves estaba caído, por orden del gobierno, y sin nada que yo pudiera hacer.
Ese es el lock-in sobre el que me niego a construir. Fable salió en las noticias. Lo que te pilla de verdad casi nunca sale: un cambio de precio, un rate limit nuevo, una retención de datos que no puedes aceptar, un modelo deprecado con un mes de aviso. Cuando dependes del modelo de un solo proveedor, cada una de esas cosas es tu problema y ninguna es tu decisión.
Una flota bajo un mismo contrato convierte eso de una caída en un cambio de config. El motor en el que confiabas desaparece, enrutas a otro, el trabajo sigue. Y el suelo debajo de todo es el open source: con cualquier modelo open source corriendo en local a través de Ollama, no sale nada de tu máquina y ningún proveedor, ni ningún gobierno, lo puede apagar. Para alguien en la UE que maneja el código fuente de otros, eso no es un lujo. Es la razón entera de construirlo así.
De lo que más orgulloso estoy es de una limitación
Esta es la decisión de diseño que más importa, y es una limitación, no una feature.
Cuando corre el router inteligente, puede elegir exactamente dos cosas: qué agente y qué perfil. Ese es todo el contrato. No puede elegir el modelo. No puede elegir el esfuerzo de razonamiento. No puede elegir el presupuesto de contexto. Eso sale de un slot de config probado, no de un modelo de lenguaje improvisando sobre la marcha.
Esto mata una clase entera de fallo que está por todas partes en los productos de IA: dejar que un modelo “decida” una config de runtime que luego no existe, no está autenticada o no encaja con el motor que ha elegido. En PaellaDoc el router propone un agente y un perfil. El runtime resuelve el modelo, el esfuerzo y el contexto desde config verificada. La parte lista sugiere. La parte aburrida y probada ejecuta.
Determinista por defecto, inteligente por contrato
El modo por defecto es deliberadamente tonto. Reglas. Sin una llamada extra a un LLM solo para decidir un modelo. Es predecible, es barato, y cuando algo va mal lo puedes depurar de verdad. La inteligencia es opt-in, y va detrás de una licencia PRO.
Y aun con el modo inteligente activado, el router va con correa corta. Si devuelve un JSON roto, o elige un motor que no está instalado, o nombra un perfil que no existe, o intenta cambiar de agente cuando había uno fijado, el sistema cae directo a reglas. Sin crash, sin ejecución a medio configurar. Determinista por defecto, inteligente por contrato.
Esa frase es toda la filosofía. En producción, la inteligencia sin fallback es deuda que todavía no te han pasado a cobrar.
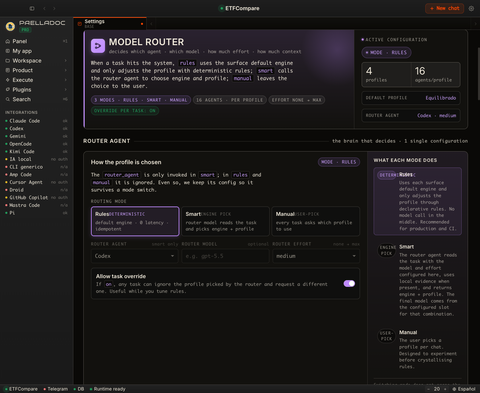
Este es el panel de verdad, no un mockup. Rules es el modo activo. La flota baja por la izquierda con la disponibilidad real de cada motor, y los tres modos están ahí: determinista por defecto, smart y manual a un clic.
Aprende, y aprende aquí
Con el tiempo el router deja de adivinar. Mira lo que de verdad ha funcionado en tu proyecto: qué combinaciones de motor y perfil han pasado el gate, y cuánto han costado en tokens. Y se inclina hacia ahí, con cuidado, solo cuando hay evidencia suficiente para justificarlo.
Dos cosas que me importan aquí. Aprende en local. No manda tus prompts ni la salida de tu terminal a ningún sitio para rankear motores. Trabaja con resultados compactos de lo que ha pasado. Y no se cree que Claude, o Codex, o Kimi sea mejor en abstracto. No tiene opinión sobre eso. Aprende qué combinaciones han funcionado en tareas como las tuyas, en tu repo.
Solo enruta a motores que pueden arrancar de verdad
Un router que te ofrece un motor que no está instalado es peor que no tener router. Antes de que ocurra siquiera la decisión inteligente, PaellaDoc filtra los candidatos a los motores que el runtime puede lanzar de verdad en esta máquina: existe el adapter, responde como disponible, está autenticado. Si un CLI local apunta a un binario fuera del PATH, el check de disponibilidad usa ese mismo path, así que no se descarta por error.
La lista de la que elige el router no es un catálogo de marketing. Es una lista de cosas que van a arrancar.
De qué va esto en realidad
Nada de esto va de un modelo mágico que siempre acierta. No creo que ese modelo exista, y un producto montado sobre la suposición de que sí se rompe la primera semana.
La próxima generación de software con agentes no se va a diferenciar por qué modelo llama. Todos llaman al mismo puñado. Se va a diferenciar por la calidad de su capa de decisión: cómo elige, cuándo escala, qué aprende, qué bloquea y cómo falla. Esa capa es el producto.
Un CLI corre el motor de un proveedor, y lo corre bien. PaellaDoc gobierna una flota de ellos, y la decisión sigue siendo tuya.
Esta es la versión larga de una fila del hub de comparativas: agnóstico de modelo, tu motor, tu máquina. Y es el mismo argumento que el resto de lo que construyo: el cerebro de producto que se mantiene solo, y un build en verde no es una feature correcta.
¿Tú enrutas entre motores o te ciñes a uno? Cuéntamelo en el foro, quiero saber cómo lo llevas.
Preguntas frecuentes
¿Qué es el routing de modelos para agentes de código?
El routing de modelos trata la tarea, no el modelo, como la unidad de trabajo. Cuando entra una tarea, un router elige qué motor la corre y con qué perfil —cheap, balanced, strong o frontier— según el tipo de tarea, qué motores están disponibles de verdad, el coste y la latencia que aceptas y qué funcionó antes. Un retoque de copy y una migración de base de datos no son el mismo trabajo, así que no deberían ir por defecto al mismo motor caro.
¿Cómo evito el vendor lock-in con los modelos de IA?
Trata los motores como una flota bajo un mismo contrato en vez de atar tu trabajo a un solo modelo. Cuando un proveedor cambia el precio, añade un rate limit o retiran un modelo —como pasó la semana en que una orden de control de exportaciones desactivó uno a mitad de semana— enrutas a otro motor y el trabajo sigue, convirtiendo una caída en un cambio de config. El suelo debajo es el open source: un modelo local a través de Ollama que ningún proveedor ni gobierno puede apagar.
¿Debería usar un solo modelo de IA o enrutar entre varios?
Para trabajo puntual, un solo CLI enrutando dentro de su proveedor sobra: Claude Code planifica con un modelo y ejecuta con otro. Deja de bastar cuando quieres un producto entre motores: ninguno va a mandar tu tarea barata a un motor, tu migración a un modelo frontier y tu trabajo offline a uno local, ni responder disponibilidad, coste y fallback entre proveedores. La capa de decisión entre motores es el producto.
¿Un router puede mandar trabajo a un modelo que no está instalado?
No debería, y uno bueno no lo hace. Un router que te ofrece un motor que no puede arrancar es peor que no tener router. Antes de cualquier decisión inteligente, los candidatos se filtran a los motores que el runtime puede lanzar de verdad en esta máquina: existe el adapter, responde como disponible y está autenticado. Y cuando el router inteligente corre, solo elige el agente y el perfil; el modelo, el esfuerzo y el contexto salen de config verificada, con un fallback determinista por reglas si algo se rompe.