
Un agente de código termina una tarea. Tests en verde, build limpio, diff ordenado. Haces merge. La pregunta nunca ha sido si el modelo es lo bastante listo. Es si puedes fiarte de que esta ejecución, la que tienes delante, es correcta, sin ejecutarla tú.
Lo he medido. La respuesta es no, no a ojo.
El montaje
He cogido una app real de Next.js y TypeScript, la he congelado en un commit y he escrito cinco features pequeñas. Cada una es una petición de una línea más cinco criterios de aceptación. Le he pasado la petición a cuatro agentes de código (Claude Sonnet, Claude Haiku, Codex y Kimi), corrí cada combinación tres veces, y puntué el resultado ejecutando el código, no leyendo el diff.
La puntuación la hace un gate aparte. Reaplica cada diff sobre una copia limpia del repo, ejecuta el código y comprueba cada criterio. El agente nunca se corrige a sí mismo. Que el build esté en verde no cuenta para nada.
Un build en verde no prueba que sea correcto
En algún momento hemos dado por bueno que “compila y los tests pasan” significa terminado. No es así. El agente ha escrito el código y, de la misma tirada, ha escrito los tests a su alrededor. Verde significa que el código está de acuerdo consigo mismo. No dice nada de si coincide con lo que querías.
Con solo la petición de una línea, el 40% de las ejecuciones han colado un fallo de corrección real. Build en verde, tests pasando, y aun así mal.
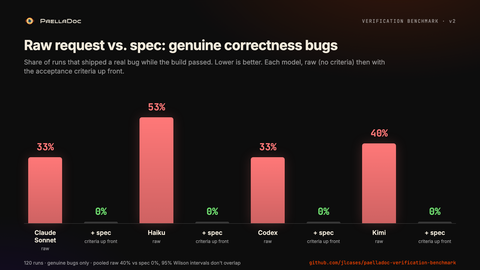
Una ejecución buena no prueba nada
Aquí está la parte que debería cambiarte la forma de trabajar. El mismo modelo, con el mismo prompt, alterna. Corre una tarea tres veces y sacas correcto, correcto, roto. En el benchmark, el 15% de las celdas se contradecían a sí mismas entre ejecuciones, y todas las inestables estaban en la rama cruda.
Los LLM no son deterministas, ni a temperatura 0. El orden en coma flotante y el batching del proveedor se encargan de eso. Así que “ha funcionado cuando lo he probado” es una sola tirada de una distribución que no ves. La ejecución que miraste y la que mergeaste no son la misma.
Por eso un modelo mejor no te salva. Un modelo más fuerte falla menos veces y de forma más plausible, lo que hace los fallos más difíciles de pillar, no más fáciles. El gate es lo que convierte una tirada con suerte en una garantía: ejecuta cada diff contra los criterios, cada vez, y cambia el “parece hecho” por “se ha ejecutado y ha pasado”.
Qué cierra el hueco
El desarrollo guiado por especificaciones es una idea pequeña, y vieja con un trabajo nuevo. Es el linaje de BDD: los criterios de aceptación del producto para una user story, escritos de forma ejecutable (piensa en el Given/When/Then de Gherkin) antes de que el agente empiece, y verificados ejecutando cuando termina. No son tests unitarios del dev. Es la definición de “hecho” del producto, convertida en el gate.
He corrido cada tarea de dos formas. Mismo modelo, mismo repo, mismo esfuerzo. Una diferencia: la rama cruda recibe la petición de una línea, la rama spec recibe esa misma petición más los cinco criterios como checklist. Agregando los cuatro modelos, en crudo ha colado un fallo real en el 40% de las ejecuciones. Con los criterios por delante, 0%. Los intervalos de confianza al 95% ni se solapan.
Y entonces el resultado que no esperaba.
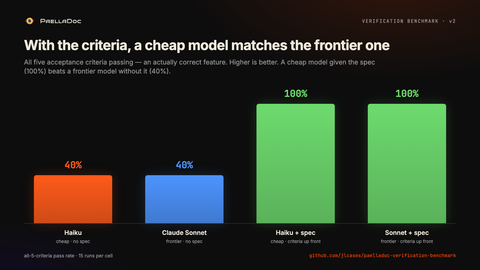
Haiku es un modelo barato. Con los criterios de aceptación, llega al 100%, a la altura del puntero. El barato con spec le ha ganado al puntero sin ella. En este benchmark, la spec ha movido más la aguja que el modelo. Es la misma lección que hay detrás de la peligrosa ilusión de la productividad con IA: la velocidad es real, la palanca está en la estructura que la rodea.
”Pero el modelo no es adivino”
Justo. Si falla un nombre de parámetro que nunca le diste, eso es cosa tuya, no un bug. Por eso cada criterio está etiquetado genuine o contract antes de cualquier ejecución, y el titular cuenta solo los genuine: peta con input vacío, caso base mal, rompe comportamiento existente, lo que un dev competente hace sin que se lo digan.
La versión profunda de esa objeción es la tesis, no un contraargumento. Sí, tienes que decirle al agente qué quieres, y comprobar que lo hizo. Eso es desarrollo guiado por especificaciones. Lo sorprendente no es que haya que especificar. Es cuánta gente no lo hace, y mergea código verde-pero-roto creyendo que está hecho.
Hasta el modelo más fuerte es una sola tirada
Así que he corrido las configs que nombraría un escéptico: Claude Opus 4.8 a esfuerzo high y max, y Codex 5.5 a razonamiento xhigh. Añadidas tras las primeras 120 como extensión etiquetada, mismo protocolo, mismo gate.
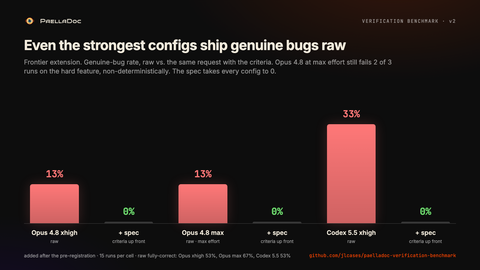
Opus 4.8 a esfuerzo máximo, la config más fuerte aquí, aun así ha colado un bug genuino en el 13% de las ejecuciones en crudo, y ha sacado una feature totalmente correcta solo el 67% de las veces. En la feature dura, ella sola, ha fallado 2 de 3 ejecuciones en crudo. Las dos configs de Opus han fallado incluso en ejecuciones distintas de esa feature, una haciendo bug, ok, bug y la otra bug, bug, ok: mismo modelo, mismo prompt, una respuesta distinta cada vez. Codex 5.5 a xhigh se ha quedado en el 33% en crudo, lo mismo que la columna de Codex en los cuatro originales. Con los criterios por delante, todas han pasado a 0% de bugs genuinos y 100% correcto.
El punto no es un ranking. Cuanto mejor el modelo, más baja la tasa de fallo en crudo, pero ninguno llega a cero, los fallos se concentran en lo que de verdad es difícil, y alternan entre ejecuciones. Hasta la config más fuerte es una sola tirada que no puedes leer sin ejecutarla. El gate es lo que hace que cualquiera sea seguro de mergear.
Intenta romperlo
El repo tiene el protocolo (escrito antes de las ejecuciones), las features, los prompts, el gate de ejecución y todos los diffs con sus veredictos. Puedes volver a puntuar cada ejecución sin pagar ni una llamada a un agente. Si encuentras por dónde se rompe el método, el hilo del foro está abierto y te respondo.
Dónde te deja esto
Esto nunca ha sido un test de IQ de modelos. Es una medida de confianza. Los modelos fuertes son buenos. Pero “bueno” y “verificado” son dos cosas distintas, y en un sistema no-determinista solo la segunda se mergea segura.
Escribe los criterios, y luego pon un gate sobre ejecutarlos. No spec-driven, donde los criterios viven en un documento, sino spec-gated, donde mandan, de modo que la spec se vuelve el contrato contra el que se comprueba cada merge. Pasan dos cosas: puedes fiarte del resultado, y un modelo barato también llega. Hacer eso a mano en cada tarea es lo que nadie mantiene. Eso es lo que PaellaDoc automatiza: convierte tu intención en criterios y mete el gate de ejecución. El principio aguanta sin la herramienta, y por eso no hay ningún producto dentro del benchmark. El modelo que pagas importa menos que el gate que no tienes.
Preguntas frecuentes
¿Un build en verde significa que la feature generada por IA es correcta?
No. El agente escribió el código y, de la misma tirada, escribió los tests a su alrededor, así que verde significa que el código está de acuerdo consigo mismo, no que coincida con lo que querías. En 120 ejecuciones de este benchmark, con solo la petición de una línea, el 40% coló un fallo de corrección real con el build en verde y los tests pasando. Compilar y ser correcto son dos afirmaciones distintas, y un build en verde solo comprueba la primera.
¿Por qué el mismo modelo pasa una tarea en una ejecución y falla en la siguiente?
Porque los LLM no son deterministas, ni a temperatura 0; el orden en coma flotante y el batching del proveedor se encargan. Corre una tarea tres veces y puedes sacar correcto, correcto, roto. En este benchmark el 15% de las celdas se contradecían entre ejecuciones. Así que «ha funcionado cuando lo he probado» es una sola tirada de una distribución que no ves, y la ejecución que miraste no es la que mergeaste.
¿Usar un modelo más capaz arregla el código verde-pero-roto?
No por sí solo. Un modelo más fuerte falla menos veces pero de forma más plausible, lo que hace los fallos más difíciles de pillar, no más fáciles. Hasta la config más fuerte medida coló un fallo genuino en una parte de las ejecuciones en crudo y alternó entre ejecuciones en la feature dura. Ninguno llegó a cero sin un gate. Lo que llevó a todos los modelos a 0% de bugs genuinos fue escribir los criterios de aceptación por delante y comprobarlos ejecutando.
¿Cómo hace fiable el código de IA el desarrollo guiado por especificaciones?
Convirtiendo los criterios de aceptación del producto en un gate de ejecución. Escribes qué significa «hecho» antes de que el agente empiece, idealmente de forma ejecutable, y luego lo verificas ejecutando el código cuando termina, cada vez. En este benchmark la rama cruda coló un fallo en el 40% de las ejecuciones y la de criterios por delante en el 0%, y un modelo barato con spec igualó a uno puntero sin ella. No spec-driven, donde los criterios viven en un documento, sino spec-gated, donde mandan.